llama.cpp Parameter erklärt: Der vollständige Guide für lokale LLM-Server

Einleitung
Wer zum ersten Mal llama-server --help aufruft, sieht eine Parameterliste, die länger ist als das letzte Pflichtenheft aus dem Büro. Keine Panik. Die meisten Flags braucht man nie. Aber die, die man braucht, sollte man verstehen — sonst läuft das Modell entweder auf der CPU, halluziniert im Kreis oder frisst mehr RAM als ein Browser mit 47 offenen Tabs.
Dieser Guide erklärt die relevanten llama.cpp Parameter Gruppe für Gruppe: Was sie machen, wann man sie setzt, und mit welchen Werten man vernünftig startet.
TL;DR
llama.cpp ist ein hochperformantes Inference-Framework für Open Weight LLMs. Die Konfiguration erfolgt ausschließlich über Kommandozeilenparameter beim Start des Servers.
- Basis: Modell laden mit
-m, optional direkt von Hugging Face via--hf-repo - Qualität:
--temp,--top-p,--top-ksteuern Kreativität vs. Determinismus - Performance:
--n-gpu-layersund--ctx-sizesind die wichtigsten Hardware-Stellschrauben - Debugging:
--log-verbosityhilft beim Verstehen, was der Server gerade tut
Was ist llama.cpp?
llama.cpp ist ein in C++ geschriebenes Inference-Framework, das das Ausführen großer Sprachmodelle (LLMs) auf Consumer-Hardware ermöglicht. Es unterstützt quantisierte Modelle im GGUF-Format und kann sowohl reine CPU-Inferenz als auch GPU-Beschleunigung über CUDA, Metal oder Vulkan nutzen.
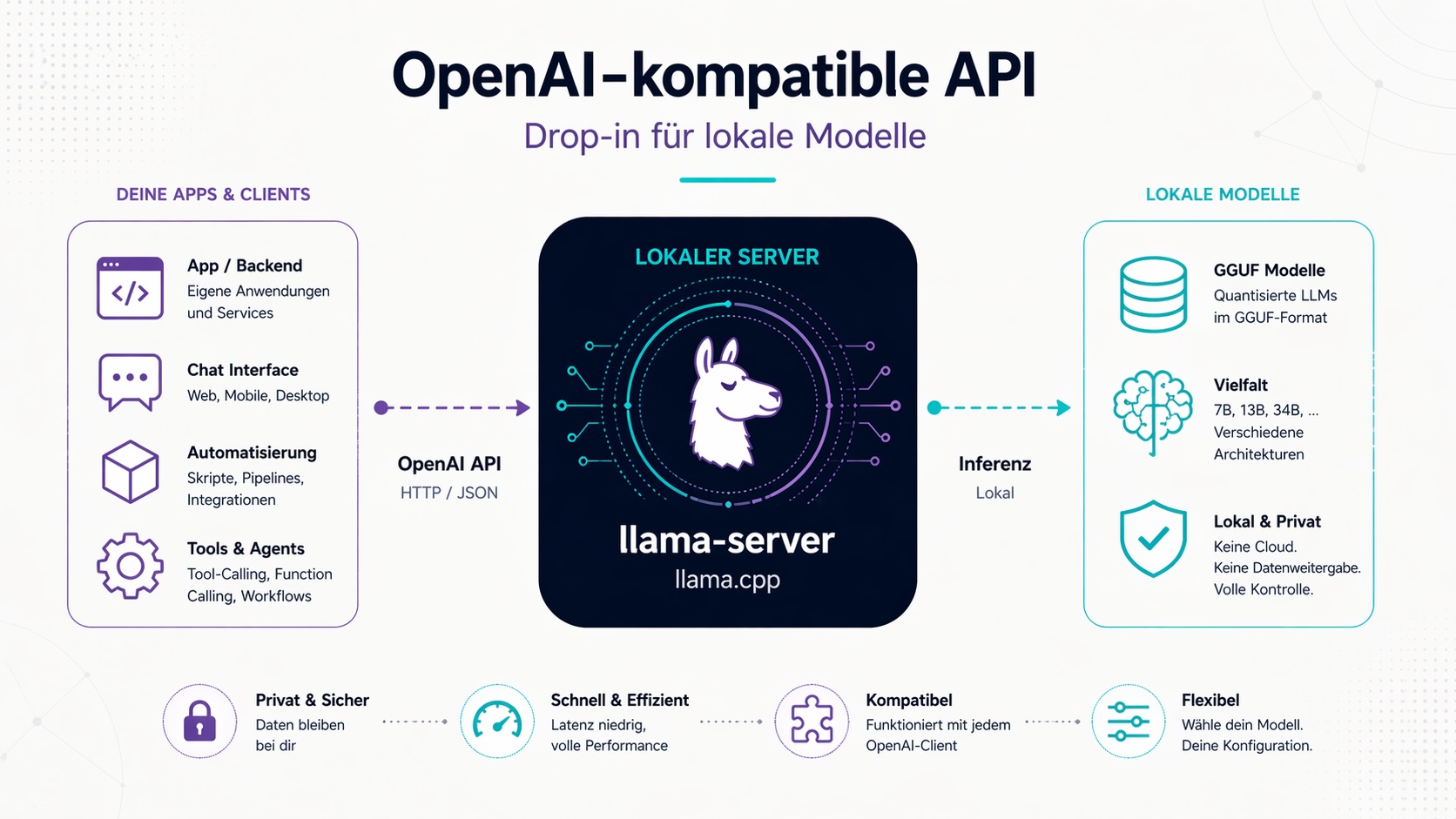
Der llama-server-Befehl startet einen lokalen HTTP-Server mit einer OpenAI-kompatiblen API. Das bedeutet: Jede Applikation, die die OpenAI-API versteht, kann direkt gegen einen lokalen llama.cpp-Server sprechen — ohne Cloud, ohne Datenweitergabe.
1. Basis & Einstieg: Server starten und Modell laden
Das Minimum, das man zum Starten braucht.
--help
Gibt die vollständige Parameterliste aus. Nützlich als schnelle Referenz, aber für tiefes Verständnis nicht ausreichend — eben deshalb dieser Artikel.
llama-server --help
--version
Zeigt die aktuelle llama.cpp-Version. Wichtig beim Debugging, weil Parameter sich zwischen Releases ändern können.
llama-server --version
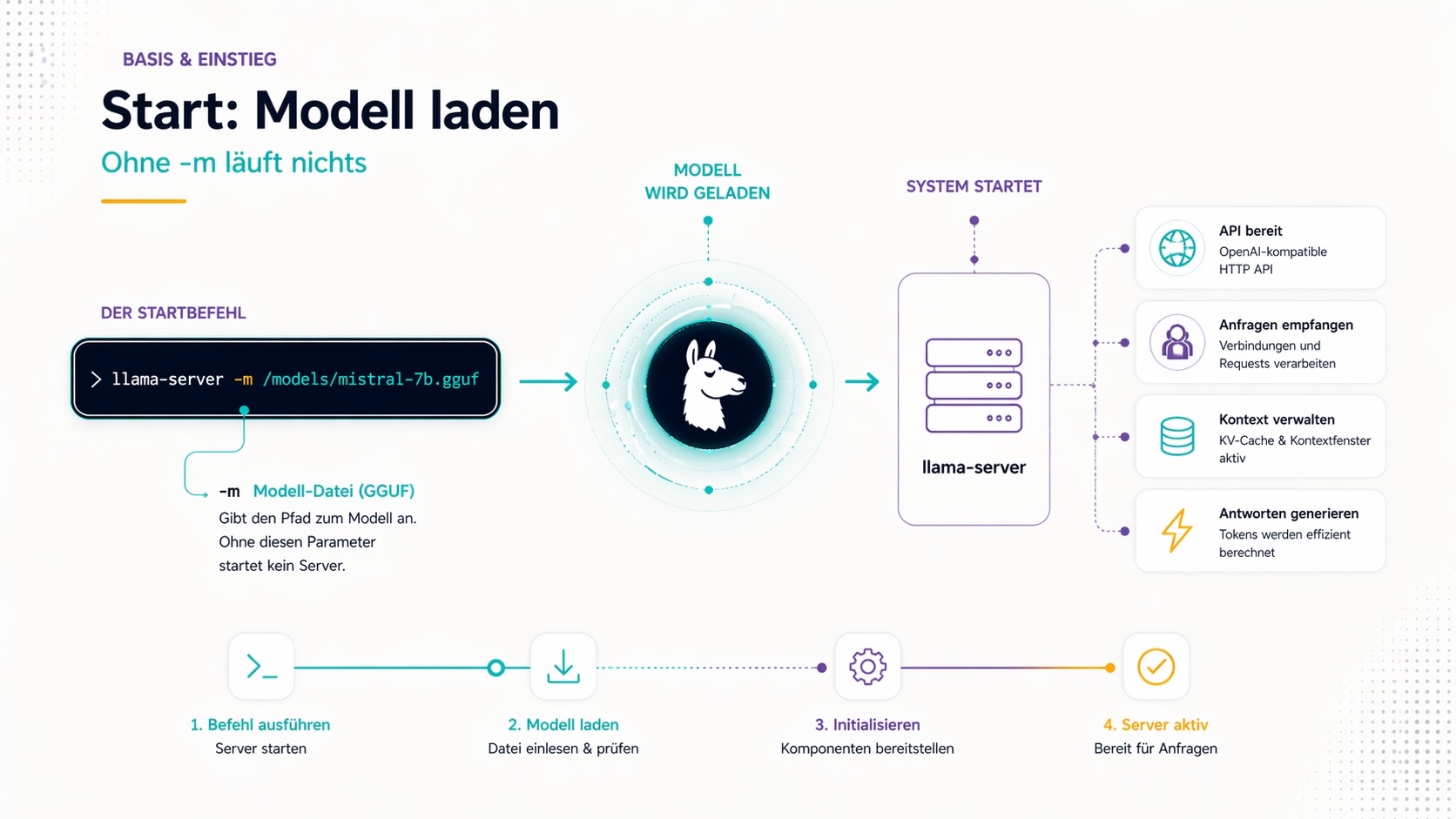
-m / --model
Der wichtigste Parameter. Gibt den Pfad zur Modelldatei an (GGUF-Format).
llama-server -m /models/mistral-7b-instruct-q4_k_m.gguf
Ohne diesen Parameter startet kein Server. Punkt.
--model-url
Lädt das Modell direkt von einer URL — z. B. von Hugging Face oder einem eigenen Fileserver. Praktisch, wenn man kein lokales Modell hat oder automatisiert deployen will.
llama-server --model-url https://huggingface.co/repo/model.gguf
--hf-repo
Kurzform für Hugging Face: Gibt organisation/repo an, llama.cpp kümmert sich um Download und Caching.
llama-server --hf-repo bartowski/Mistral-7B-Instruct-v0.3-GGUF
--hf-repo vs. --model-url: --hf-repo ist einfacher und nutzt den HF-Hub direkt inklusive Versionierung. --model-url ist flexibler und funktioniert mit beliebigen HTTPS-Quellen — z. B. für private Modell-Repositories.
2. Server & Produktion: API-Betrieb konfigurieren
Diese Parameter bestimmen, wie der Server erreichbar ist und sich in einer Infrastruktur verhält.
--host
IP-Adresse, auf der der Server lauscht. Standard ist 127.0.0.1 (nur lokal erreichbar). Für Netzwerkzugriff auf 0.0.0.0 setzen.
llama-server -m model.gguf --host 0.0.0.0
Sicherheitshinweis: 0.0.0.0 ohne --api-key bedeutet: jeder im Netz kann anfragen. In produktiven oder öffentlich erreichbaren Umgebungen immer absichern.
--port
Port des Servers. Standard: 8080.
llama-server -m model.gguf --port 8081
--api-key
Setzt einen statischen API-Key. Anfragen ohne korrekten Authorization: Bearer <key>-Header werden abgelehnt.
llama-server -m model.gguf --api-key mein-geheimer-schlüssel
Für lokale Einzelnutzung oft nicht nötig — für Netzwerkbetrieb oder containerisierte Setups empfohlen.
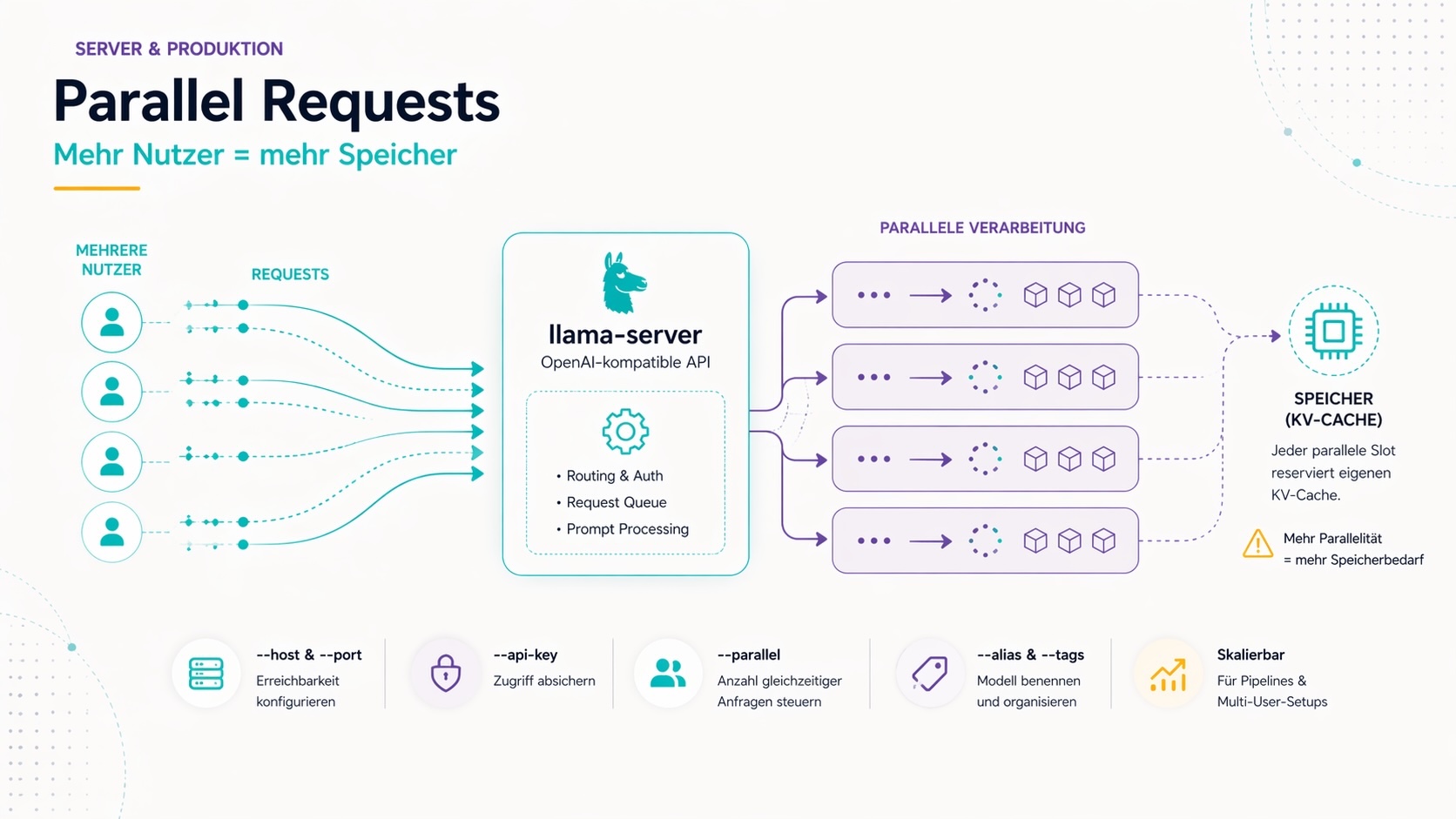
--parallel
Anzahl gleichzeitig verarbeitbarer Anfragen. Jeder parallele Slot reserviert Speicher für einen eigenen KV-Cache.
llama-server -m model.gguf --parallel 4
Für Einzelbetrieb (ein Nutzer, eine Pipeline) reicht --parallel 1. Für Multi-User-Setups oder parallele API-Calls entsprechend erhöhen — aber: mehr parallele Slots = mehr VRAM/RAM-Bedarf.
--alias
Gibt dem Modell einen Namen, der in der API-Antwort (Feld model) zurückgegeben wird. Nützlich, wenn Clients einen bestimmten Modellnamen erwarten.
llama-server -m model.gguf --alias gpt-4o
So kann eine Applikation, die gpt-4o als Modellnamen erwartet, nahtlos gegen den lokalen Server laufen.
--tags
Metadaten-Tags für das Modell. Werden in der /v1/models-Response zurückgegeben — hilfreich zur Organisation in Multi-Modell-Setups.
llama-server -m model.gguf --tags instruct,coding
3. Modellverhalten & Qualität: Antworten steuern
Diese Parameter bestimmen, wie das Modell Tokens samplet — also wie "kreativ", "fokussiert" oder "deterministisch" die Antworten sind.
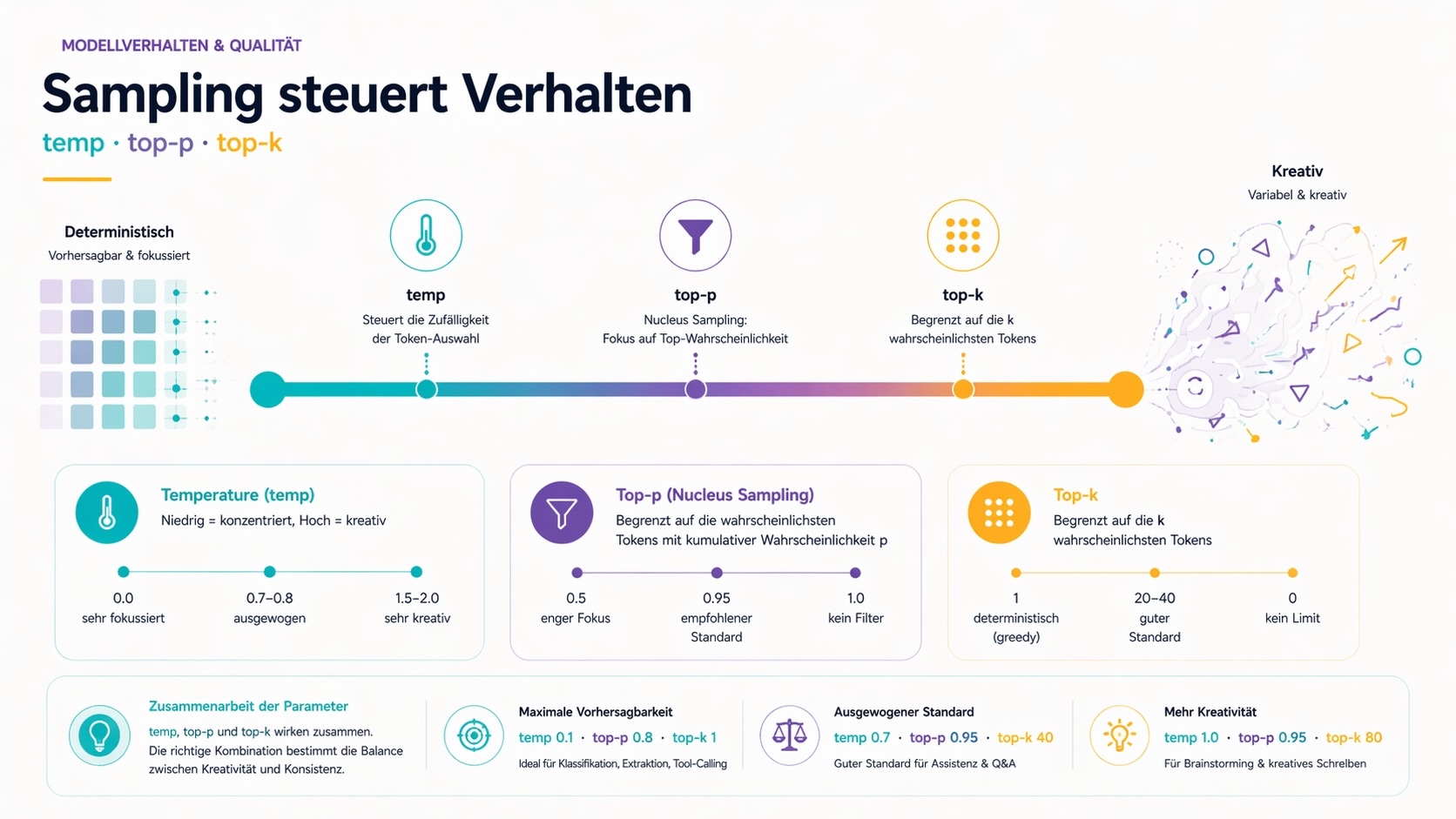
--temp (Temperature)
Steuert die Zufälligkeit der Token-Auswahl. Werte zwischen 0.0 und 2.0, Standard meist 0.8.
- Niedrig (0.0–0.3): Deterministisch, immer die wahrscheinlichste Fortsetzung. Gut für Klassifikation, strukturierte Extraktion, Tool-Calling.
- Mittel (0.5–0.8): Ausgewogene Antworten. Guter Standard für Assistenz-Aufgaben.
- Hoch (1.0–2.0): Kreativ und variabel. Für Brainstorming oder kreatives Schreiben.
llama-server -m model.gguf --temp 0.2
Praxisbeispiel: In einer Klassifikationspipeline (z. B. für thematische Einordnung von Texten) arbeite ich mit --temp 0.1 — das Modell soll konsistent dieselbe Kategorie zurückgeben, nicht kreativ variieren.
--top-p (Nucleus Sampling)
Begrenzt die Token-Auswahl auf die wahrscheinlichsten Tokens, deren kumulative Wahrscheinlichkeit p nicht überschreitet. Standard: 0.95.
1.0= alle Tokens werden berücksichtigt (kein Filter)0.9= nur Tokens aus dem oberen 90%-Wahrscheinlichkeitsbereich0.5= sehr enger Fokus auf die sichersten Fortsetzungen
--top-p und --temp wirken zusammen. Niedriges --temp + niedriges --top-p = maximale Vorhersagbarkeit.
llama-server -m model.gguf --temp 0.3 --top-p 0.9
--top-k
Begrenzt die Auswahl auf die k wahrscheinlichsten nächsten Tokens. Standard: 40.
1= immer das wahrscheinlichste Token (greedy decoding, deterministisch)40= guter Standardwert0= deaktiviert (kein Limit)
--top-k filtert vor --top-p. Wer deterministische Ausgaben will, setzt --top-k 1 — das überstimmt auch --temp.
llama-server -m model.gguf --top-k 20
--repeat-penalty
Bestraft Tokens, die kürzlich bereits ausgegeben wurden. Standard: 1.1.
1.0= keine Penalty> 1.0= Wiederholungen werden unwahrscheinlicher< 1.0= Wiederholungen werden wahrscheinlicher (selten sinnvoll)
Praxishinweis für Tool-Calling: --repeat-penalty kann helfen, Loops zu stabilisieren, bei denen das Modell denselben Tool-Call endlos wiederholt. Vorsicht aber: zu hohe Werte (> 1.3) können die Ausgabequalität verschlechtern, weil das Modell auch sinnvolle Wiederholungen vermeidet.
llama-server -m model.gguf --repeat-penalty 1.15
--reasoning
Aktiviert Chain-of-Thought-Reasoning für Modelle, die es unterstützen (z. B. DeepSeek-R1, QwQ). Das Modell gibt einen internen Denkprozess aus, bevor es die finale Antwort liefert.
llama-server -m deepseek-r1.gguf --reasoning
Nur sinnvoll mit Modellen, die explizit für Reasoning-Output trainiert wurden.
--jinja
Aktiviert Jinja2-basiertes Chat-Template-Rendering. Wird benötigt, wenn das Modell ein spezifisches Prompt-Format erwartet (z. B. <|im_start|>user-Syntax bei Qwen oder spezifische System-Prompt-Strukturen).
llama-server -m model.gguf --jinja
Für Tool-Calling wichtig: Die Qualität von Function Calling hängt stark davon ab, ob das korrekte Prompt-Template angewendet wird. --jinja in Kombination mit einem gut gepflegten Template im Modell-Metadata verbessert Tool-Calling-Zuverlässigkeit deutlich.
4. Performance & Hardware: Geschwindigkeit und Speicher optimieren
Hier entscheidet sich, ob das Modell auf der GPU läuft oder auf der CPU schläft.
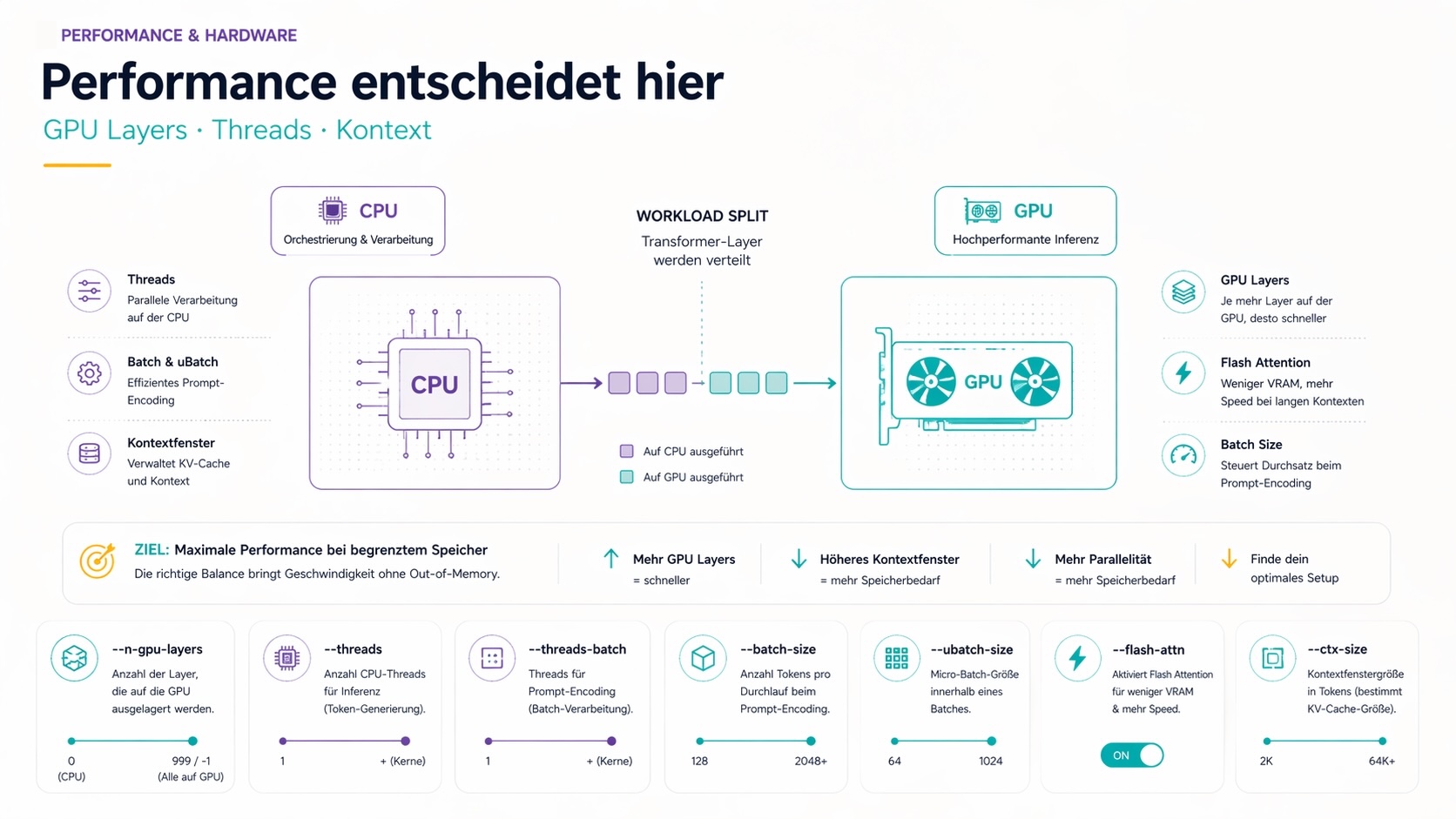
--n-gpu-layers
Der wichtigste Performance-Parameter. Gibt an, wie viele Transformer-Layer auf die GPU ausgelagert werden. Jeder Layer bedeutet mehr GPU-Nutzung — und deutlich höhere Geschwindigkeit.
0= alles auf CPU (langsam, aber funktional ohne GPU)999oder-1= alle Layer auf GPU (schnellste Option, wenn VRAM reicht)- Zwischenwerte = Hybrid: GPU übernimmt die angegebene Anzahl Layer, Rest bleibt auf CPU
llama-server -m model.gguf --n-gpu-layers 35
Faustregel: Modellgröße (quantisiert) + KV-Cache muss in den VRAM passen. Ein 7B Q4-Modell braucht ca. 4–5 GB. Ausprobieren: mit --n-gpu-layers 999 starten, bei Out-of-Memory-Fehler schrittweise reduzieren.
--threads
Anzahl der CPU-Threads für Inferenz (Token-Generierung). Standard: Systemwert (oft alle physischen Kerne).
llama-server -m model.gguf --threads 8
Mehr Threads ist nicht automatisch schneller — bei GPU-lastiger Inferenz ist der CPU-Anteil gering. Für reine CPU-Inferenz: physische Kernanzahl minus 1–2 (für OS-Tasks) als Startwert.
--threads-batch
Threads speziell für die Batch-Verarbeitung (Prompt-Encoding / Prefill-Phase). Kann von --threads abweichen.
llama-server -m model.gguf --threads 4 --threads-batch 8
Für Pipelines mit langen Prompts kann ein höherer --threads-batch-Wert die Verarbeitungszeit der Input-Tokens reduzieren.
--batch-size
Anzahl der Tokens, die in einem Durchlauf während des Prompt-Encodings verarbeitet werden. Standard: 2048.
llama-server -m model.gguf --batch-size 512
Höhere Werte = schnelleres Prompt-Encoding, aber mehr Speicherbedarf. Bei VRAM-Engpässen reduzieren.
--ubatch-size
Micro-Batch-Größe innerhalb eines Batches. Steuert die interne Aufteilung der Batch-Verarbeitung. Standard: 512.
llama-server -m model.gguf --ubatch-size 256
Relevan bei VRAM-Optimierung: Kleinere --ubatch-size reduziert Peak-Speicherbedarf auf Kosten leicht schlechterer Durchsatz.
--flash-attn
Aktiviert Flash Attention — eine speichereffiziente Implementierung des Attention-Mechanismus. Reduziert VRAM-Bedarf bei langen Kontexten erheblich und beschleunigt die Inferenz.
llama-server -m model.gguf --flash-attn
Empfehlung: Immer aktivieren, wenn die GPU Flash Attention unterstützt (CUDA ab Ampere, neuere Apple Silicon). Kein Nachteil, klarer Gewinn bei langen Kontexten.
--fit und --fit-target
--fit aktiviert automatische Anpassung der Layer-Verteilung, um in den verfügbaren VRAM zu passen. --fit-target gibt den Ziel-VRAM in Bytes an.
llama-server -m model.gguf --fit --fit-target 6442450944
Praktisch als Alternative zu manuellem --n-gpu-layers-Tuning: llama.cpp berechnet selbst, wie viele Layer passen.
--ctx-size
Kontextfenstergröße in Tokens. Bestimmt, wie viel Text das Modell "sieht" (Prompt + bisherige Antwort). Standard variiert je nach Modell, oft 2048 oder 4096.
llama-server -m model.gguf --ctx-size 8192
Wichtig: Der KV-Cache wächst quadratisch mit der Kontextgröße. Ein großes Kontextfenster kann VRAM und RAM schnell erschöpfen — besonders in Kombination mit --parallel. Nicht größer setzen als nötig.
5. Speicher & Loading-Verhalten
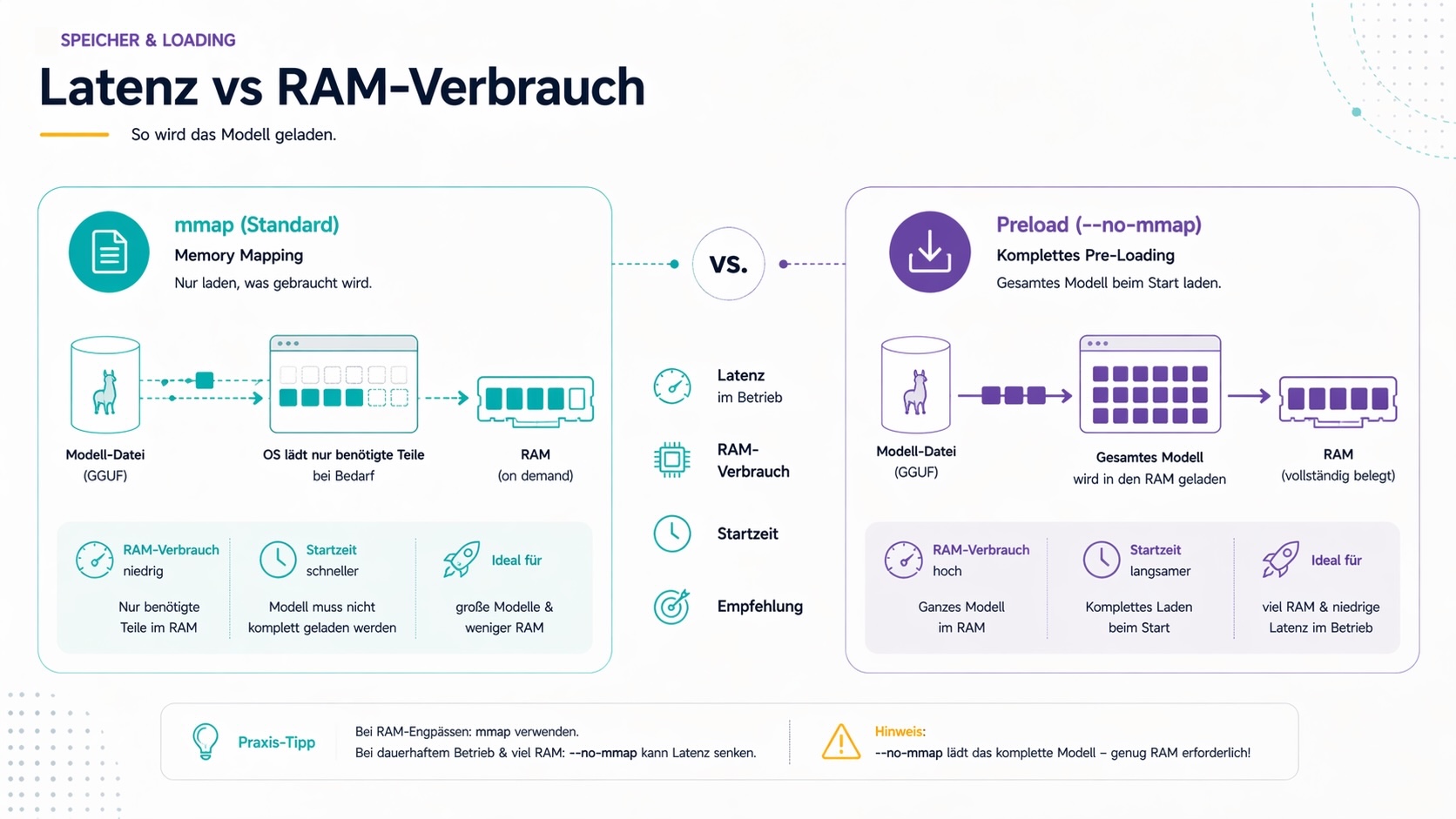
--mmap / --no-mmap
Memory Mapping (mmap) ist standardmäßig aktiviert. Das Betriebssystem lädt dabei nur die Teile des Modells in den RAM, die gerade gebraucht werden — ähnlich wie ein Buch, aus dem man nur die aktuelle Seite hält.
--mmap(Standard): Effizient für große Modelle, nutzt OS-Caching--no-mmap: Lädt das komplette Modell beim Start in den RAM
llama-server -m model.gguf --no-mmap
Wann --no-mmap sinnvoll ist: Bei häufigen Anfragen und ausreichend RAM kann vollständiges Pre-Loading die Latenz reduzieren, weil kein Page-Fault-Overhead entsteht. Bei RAM-Engpässen ist --mmap die bessere Wahl.
6. Multimodalität
--mmproj
Lädt ein Multimodal-Projektions-Modell — die Komponente, die Bilder in den Token-Raum des LLMs übersetzt. Notwendig für Vision-fähige Modelle wie LLaVA, BakLLaVA oder Qwen-VL.
llama-server -m llava-7b.gguf --mmproj llava-clip-vit.gguf
Ohne passendes --mmproj können Vision-Modelle keine Bilder verarbeiten — nur Text.
7. Logging & Debugging
Wenn der Server sich seltsam verhält, helfen diese Parameter beim Verstehen, was intern passiert.

--log-verbosity
Detailgrad der Log-Ausgabe. Höhere Werte = mehr Output.
llama-server -m model.gguf --log-verbosity 2
0 für minimalen Output im Produktionsbetrieb, 2–3 beim Debugging von Performance oder unerwartetem Modellverhalten.
--log-timestamps
Fügt jedem Log-Eintrag einen Zeitstempel hinzu. Wichtig für Performance-Analyse und Nachvollziehbarkeit in Pipelines.
llama-server -m model.gguf --log-timestamps
--log-colors
Färbt Log-Output ein (Info, Warning, Error in unterschiedlichen Farben). Erleichtert das schnelle Erkennen von Fehlern im Terminal.
llama-server -m model.gguf --log-colors
Für Logs in Dateien oder Container-Log-Systeme ohne Farb-Unterstützung deaktivieren.
--log-file
Schreibt Logs in eine Datei statt nur auf stdout.
llama-server -m model.gguf --log-file /var/log/llama-server.log
Für dauerhaft laufende Server empfohlen — erleichtert späteres Debugging.
8. Praxisbeispiel: Mein lokales Setup
Für den Betrieb von OpenClaw auf meinem Heimserver läuft ein llama.cpp-Server in einem dedizierten Container.
Das Setup ist auf ein einzelnes Modell optimiert — Gemma 4 26B, quantisiert auf Q4_K_M. Der vollständige Startbefehl:
/opt/llama.cpp/build/bin/llama-server \
-m /home/easy/models/gemma-4-26B-it/gemma-4-26B-A4B-it-UD-Q4_K_M.gguf \
--host 0.0.0.0 \
--port 8080 \
--ctx-size 65536 \
--threads 6 \
--threads-batch 6 \
--batch-size 1024 \
--ubatch-size 512 \
--parallel 1 \
--jinja \
--reasoning off \
--temp 0.75 \
--top-p 0.95 \
--top-k 64 \
--no-mmap \
--flash-attn on \
--fit on \
--fit-target 256 \
--log-timestamps \
--log-verbosity 2
Was dahinter steckt:
--ctx-size 65536— großes Kontextfenster für lange Konversationen in OpenClaw;--flash-attn onmacht das bei diesem Modell erst praktikabel--fit on --fit-target 256— automatische Layer-Verteilung auf den verfügbaren VRAM, kein manuelles Tuning von--n-gpu-layersnötig--no-mmap— Modell wird vollständig in den RAM geladen; beim Dauerbetrieb auf einem Heimserver reduziert das die Latenz, weil kein Page-Fault-Overhead entsteht--jinja— notwendig für korrekte Chat-Template-Verarbeitung bei Gemma 4; direkt relevant für Tool-Calling-Qualität in OpenClaw--reasoning off— Gemma 4 unterstützt Reasoning-Output, für den Assistenz-Betrieb ist er hier deaktiviert--temp 0.75mit--top-p 0.95und--top-k 64— ausgewogenes Sampling für natürliche Konversation ohne übermäßige Kreativität--parallel 1— Einzelnutzer-Setup, kein Multi-User-Betrieb nötig--threads 6/--threads-batch 6— auf die CPU-Konfiguration des Heimservers abgestimmt
Die API ist unter http://<server-ip>:8080 erreichbar und vollständig OpenAI-kompatibel — der Drop-in für OpenClaw.
Häufige Fehler & Hinweise
- CUDA out of memory:
--n-gpu-layersreduzieren oder--ctx-sizeverkleinern.--flash-attnaktivieren, falls noch nicht gesetzt. - Langsame Inferenz trotz GPU: Prüfen ob
--n-gpu-layersgesetzt ist — Standard ist 0 (CPU). - Tool-Calling-Loops:
--repeat-penaltyauf 1.1–1.2 erhöhen,--tempsenken,--jinjaaktivieren und Chat-Template prüfen. - Hoher RAM-Verbrauch beim Start:
--mmap(Standard) verwenden statt--no-mmap. - Modell gibt immer dieselbe Antwort:
--top-k 1oder--temp 0prüfen — beides erzwingt greedy decoding.
FAQ
Welche Parameter sind für den Einstieg wirklich wichtig?
Für den ersten Start reichen -m (Modellpfad), --n-gpu-layers (GPU-Nutzung) und --ctx-size (Kontextgröße). Alles andere hat sinnvolle Standardwerte.
Was passiert, wenn ich --n-gpu-layers zu hoch setze?
Der Server gibt beim Start einen Out-of-Memory-Fehler aus und beendet sich. Einfach den Wert schrittweise reduzieren, bis es passt.
Kann ich llama.cpp mit OpenAI-Client-Bibliotheken nutzen?
Ja. Der Server implementiert die OpenAI-API. base_url auf die lokale Adresse setzen, api_key auf einen beliebigen String (oder den gesetzten Key) — fertig.
Was ist der Unterschied zwischen --temp 0 und --top-k 1?
Beide erzwingen deterministisches Verhalten, aber auf verschiedenen Ebenen. --top-k 1 wählt immer das wahrscheinlichste Token direkt. --temp 0 macht alle Nicht-Top-Tokens so unwahrscheinlich, dass sie praktisch nie gewählt werden. Das Ergebnis ist ähnlich, der Mechanismus unterschiedlich.
Lohnt sich --flash-attn immer?
Ja, wenn die GPU es unterstützt. Es spart VRAM und beschleunigt Inferenz bei längeren Kontexten. Kein bekannter Nachteil für normale Nutzung.
Wann sollte ich --parallel erhöhen?
Wenn mehrere Clients gleichzeitig Anfragen stellen oder eine Pipeline parallele API-Calls macht. Jeder Slot braucht eigenen KV-Cache-Speicher — VRAM/RAM entsprechend im Blick behalten.
Fazit
llama.cpp ist mächtig — aber die meisten Parameter haben vernünftige Standardwerte. Für den Einstieg genügt ein Fokus auf --n-gpu-layers, --ctx-size und die Sampling-Parameter (--temp, --top-p, --top-k). Wer produktive Pipelines betreibt, sollte zusätzlich Logging konfigurieren und --flash-attn aktivieren.
Die wichtigste Erkenntnis: Parametrisierung ist keine einmalige Entscheidung. Use Case bestimmt Konfiguration — ein Kreativtext-Assistent braucht andere Sampling-Werte als eine Extraktionspipeline.
Autor: Erik Weber