Kontext ist
das Betriebssystem.
Wie Agents wissen, was relevant ist. Und warum Kontext das eigentliche Betriebssystem von KI wird.
Die Qualität agentischer Systeme hängt stärker von Kontextarchitektur ab als von reiner Modellintelligenz. Relevanter Kontext zur richtigen Zeit schlägt jedes größere Modell.
Ein LLM ohne Kontext kennt dein Unternehmen nicht, deine Projekte nicht, deine Ziele nicht. Es rät. Die eigentliche Frage moderner KI-Systeme lautet selten „Wie intelligent ist das Modell?“, sondern „Wie gut ist die Kontextbereitstellung?“ Genau dafür gibt es bis heute keinen Standard. Jedes ernsthafte Agentensystem baut sich seine eigene Kontextarchitektur.
Das eigentliche Problem ist Kontext.
Selbst sehr starke Modelle werden ohne Kontext schnell unbrauchbar. Sie kennen weder dein Unternehmen, deine Projekte, deine Ziele noch deine Arbeitsweise. Was fehlt, ist nicht Intelligenz, sondern relevante Information.
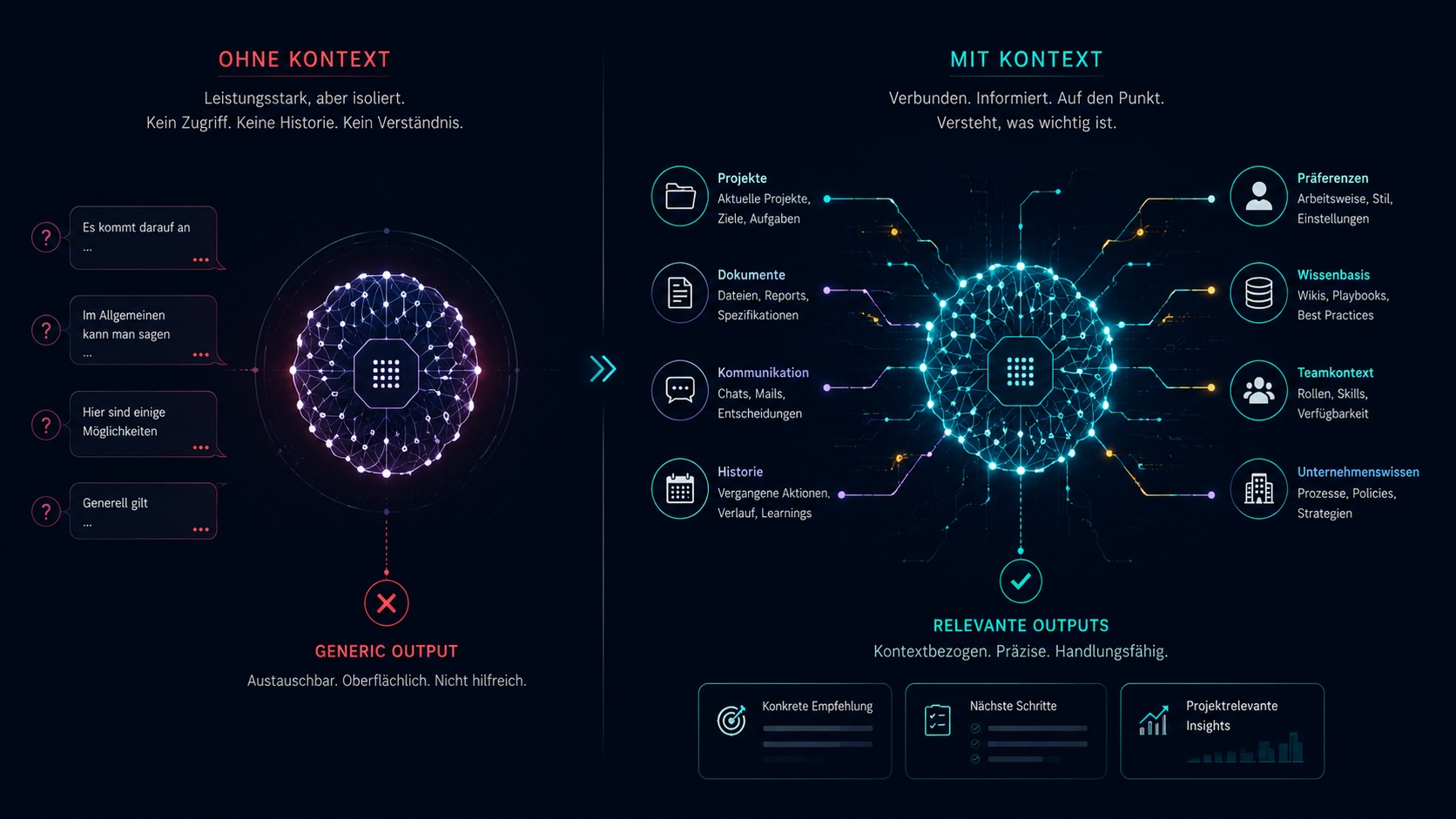
- 01Modell allein.
Isoliert, ohne Zugriff, ohne Historie. Antworten bleiben generisch, egal wie gut das Modell ist.
- 02Modell mit Kontext.
Verbunden mit Projekten, Wissen, Dokumenten, Präferenzen. Antworten werden anschlussfähig, präzise, brauchbar.
Kontext macht aus generischer KI arbeitsfähige KI.
Wichtig: Das ist bis heute kein gelöstes Standardproblem. Es gibt keine fertige Architektur. Jedes ernsthafte Agentensystem baut eigene Strukturen.
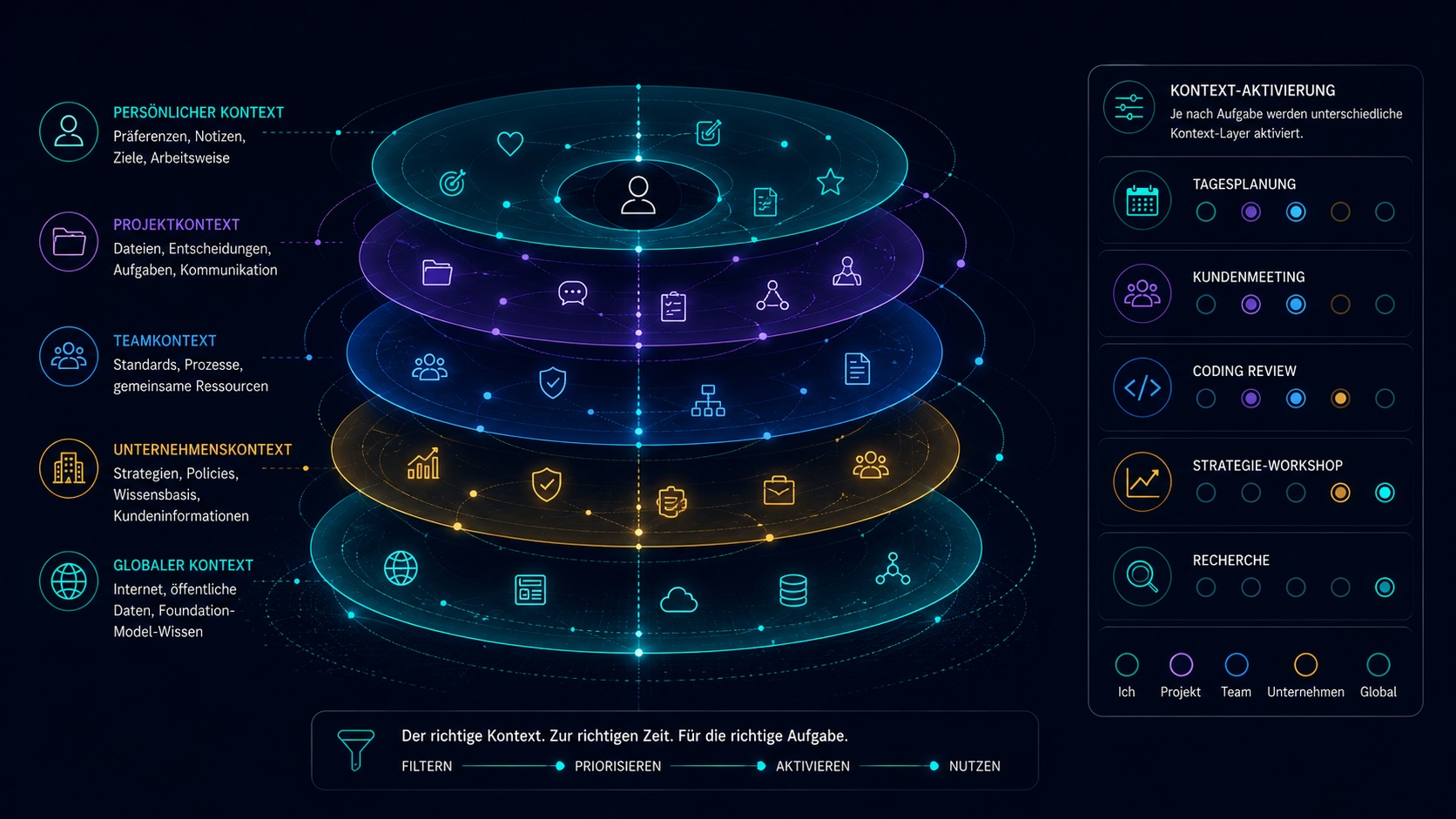
Kontext ist geschichtet.
Nicht jede Information gehört jedem Agenten, jedem Nutzer, jedem Projekt. Guter Kontext ist scoped, geschichtet und dynamisch. Kein gigantischer gemeinsamer Datensumpf.
Persönlich
Präferenzen, Notizen, Ziele, Arbeitsweise.
Projekt
Dateien, Entscheidungen, Aufgaben, Kommunikation.
Team
Standards, Prozesse, gemeinsame Ressourcen.
Unternehmen
Strategien, Policies, Wissensbasis, Kundeninformationen.
Global
Internet, öffentliche Daten, Foundation-Model-Wissen.
Gute Agentensysteme aktivieren den richtigen Kontext zur richtigen Zeit für die richtige Aufgabe.
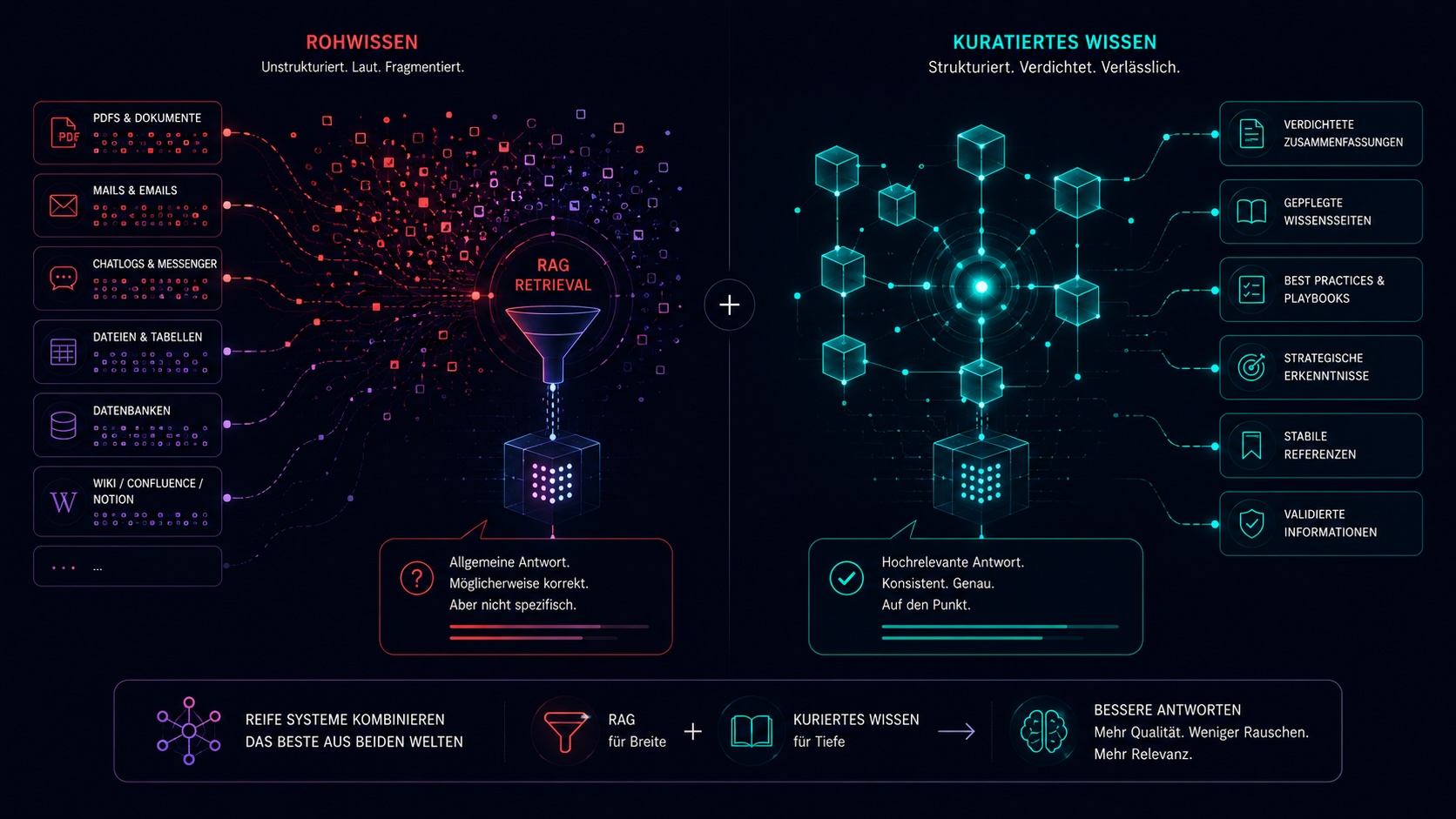
RAG, Wikis und Wissenszugriff.
RAG, Memory, Datenbanken, Wikis. Wird oft durcheinandergeworfen. Die wichtigste Klarstellung: RAG ist ein Zugriffsmuster, kein Gedächtnis. Es beantwortet „Wie finde ich relevante Informationen?“. Nicht „Was speichere ich überhaupt dauerhaft?“
- PDFs
- SharePoint
- Notion
- Confluence
- Mailarchive
- Datenbanken
- verdichtete Zusammenfassungen
- gepflegte Wissensseiten
- stabile Best Practices
- strategische Erkenntnisse
- geprüfte Referenzen
Reife Systeme kombinieren Rohwissen und kuratiertes Wissen.
Nicht jedes Wissen sollte jedes Mal neu aus Rohdaten rekonstruiert werden. Manche Erkenntnisse verdienen einen festen Platz.
Kontextengineering.
Kontext entsteht nicht automatisch. Jemand muss entscheiden, welche Daten relevant sind, wann sie geladen werden, welche priorisiert, verborgen oder verdichtet werden. Das nennt sich Kontextengineering. Und ist heute eine der unterschätztesten Disziplinen agentischer Systeme.
- 01Nicht zu wenig Daten.
Das eigentliche Problem ist selten Datenmangel, sondern zu viele irrelevante Daten, die das Modell ablenken.
- 02Schlechter Kontext schadet.
Selbst starke Modelle werden schlechter, wenn der Kontext widersprüchlich, veraltet oder verrauscht ist.
Was Kontextengineering entscheidet:
Die Zukunft gehört nicht den Firmen mit den meisten Daten, sondern denen mit den besten Kontextsystemen.
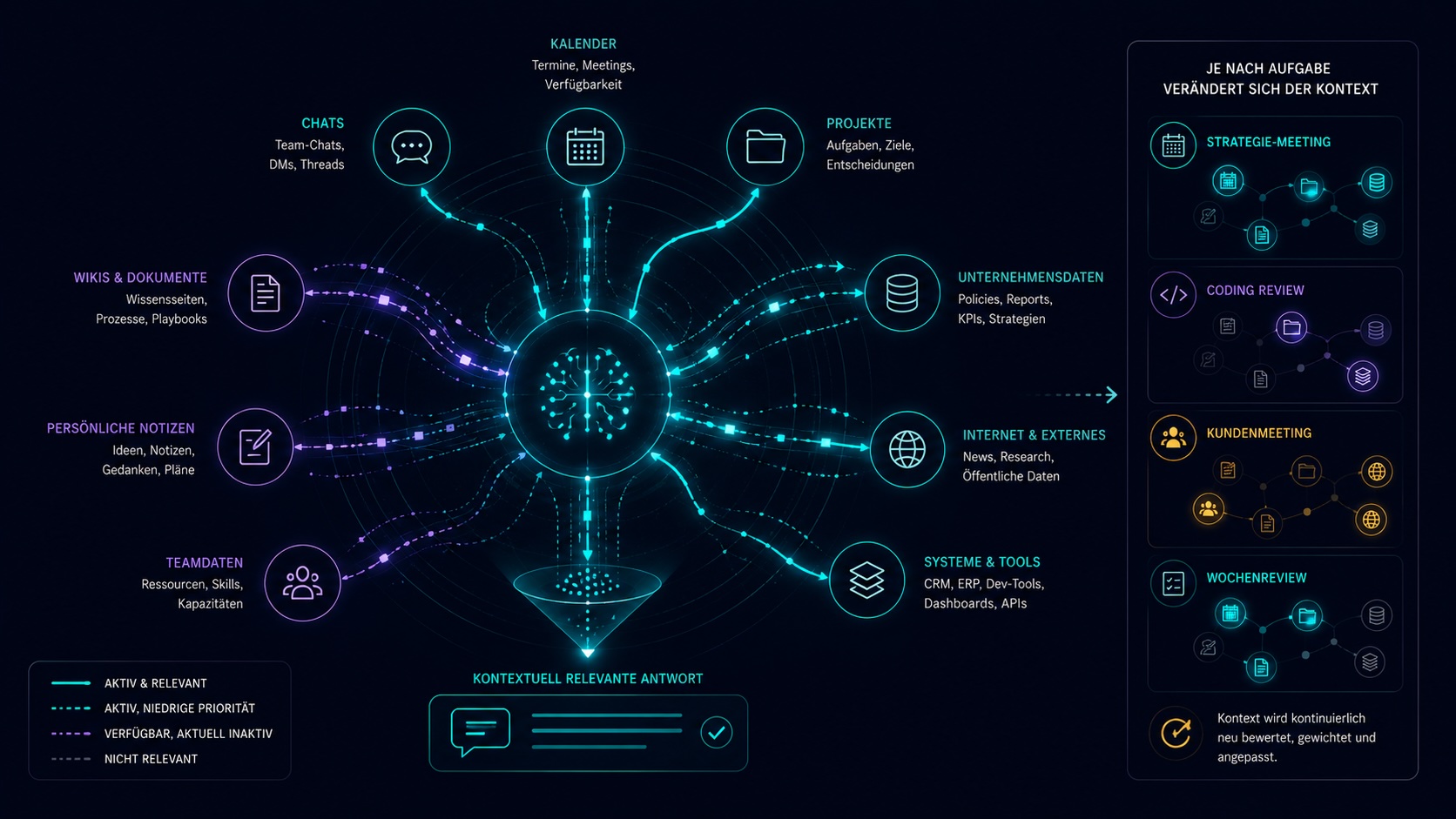
Kontext ist dynamisch.
Relevanter Kontext verändert sich ständig. Er hängt ab von Aufgabe, Rolle, Zeit, Prioritäten, Projekten und Beziehungen. Der Agent braucht morgens andere Informationen als im Strategie-Meeting, beim Kunden oder im Wochenreview.
- was wird gerade gemacht?
- welcher Output ist gefragt?
- welche Tiefe ist nötig?
- wer fragt?
- welche Rechte?
- welche Perspektive?
- Zeitpunkt
- Prioritäten
- laufende Projekte
- Beziehungen
Kontext ist kein statischer Speicher. Kontext ist ein aktiver Datenfluss.
Die ungelöste Herausforderung.
Es gibt hunderte Tools, Vektordatenbanken, Frameworks und Memory-Systeme. Aber kaum stabile Standards. Wir bauen gerade die ersten Betriebssysteme für agentische Arbeit. Keine fertigen Endprodukte.
Was speichern?
Welche Informationen verdienen Langzeit-Status, welche bleiben flüchtig?
Was vergessen?
Wie verhindert man Datenmüll und Drift in lange laufenden Systemen?
Wer darf was?
Welcher Agent, welche Rolle, welcher Mensch sieht welche Schicht?
Wie validieren?
Wie wird Wissen bestätigt, korrigiert, versioniert?
Wie aktuell halten?
Wie verhindert man, dass Kontext zur Karteileiche wird?
Wie strukturieren?
Welche Form lässt sich auffinden, kombinieren, wiederverwenden?
Wir bauen gerade die ersten Betriebssysteme für agentische Arbeit.
Vier Heuristiken für eigene Kontextsysteme.
Auch ohne fertigen Standard kann man gute Entscheidungen treffen. Vier einfache Regeln machen den Unterschied zwischen Datensumpf und arbeitsfähigem Kontextsystem.
- 01Layer scopen.
Persönlich · Projekt · Team · Unternehmen sauber trennen. Nicht alles ist für jeden.
- 02Kuratieren statt sammeln.
Verdichtete Wissensseiten schlagen verstreute Rohdaten. Pflege geht vor Vollständigkeit.
- 03Dynamisch aktivieren.
Nur laden, was zur Aufgabe passt. Lieber zwei relevante Quellen als zehn zufällige.
- 04Aktuell halten.
Owner pro Wissensbereich. Update-Rhythmus festlegen. Veraltetes markieren oder löschen.
Die Zukunft agentischer Systeme hängt stärker ab von Kontextarchitektur. Als von reiner Modellintelligenz.
Nicht möglichst viele Daten. Sondern relevanter Kontext, zur richtigen Zeit, in der richtigen Tiefe, für die richtige Aufgabe.
Wenn Kontext bereitsteht. Wie entsteht daraus langfristiges Lernen? Damit kommen wir zum nächsten Modul: Memory-Systeme & lernende Agenten.
Vier Bewegungen. Mehr braucht es nicht, um Kontext nutzbar zu machen.
- 01Schichten
Persönlich, Projekt, Team, Unternehmen, Global sauber trennen.
- 02Kuratieren
Rohwissen und verdichtete Wissensseiten kombinieren.
- 03Aktivieren
Dynamisch laden, was zur Aufgabe passt. Nicht alles, immer.
- 04Pflegen
Owner, Update-Rhythmus, Drift verhindern.
Das eigentliche Betriebssystem zukünftiger KI-Systeme ist Kontext.