Der Agent baut sich
selbst zusammen.
Wie sich moderne Agenten ihren Arbeitskontext dynamisch selbst zusammenbauen.
Die Zukunft liegt nicht in immer größeren Kontextfenstern, sondern in intelligenter Kontext-Orchestrierung. Der Agent der Zukunft ist eine dynamische Komposition aus Rollen, Skills, Wissen, Memory, Tools und Instruktionen. Je nach Aufgabe.
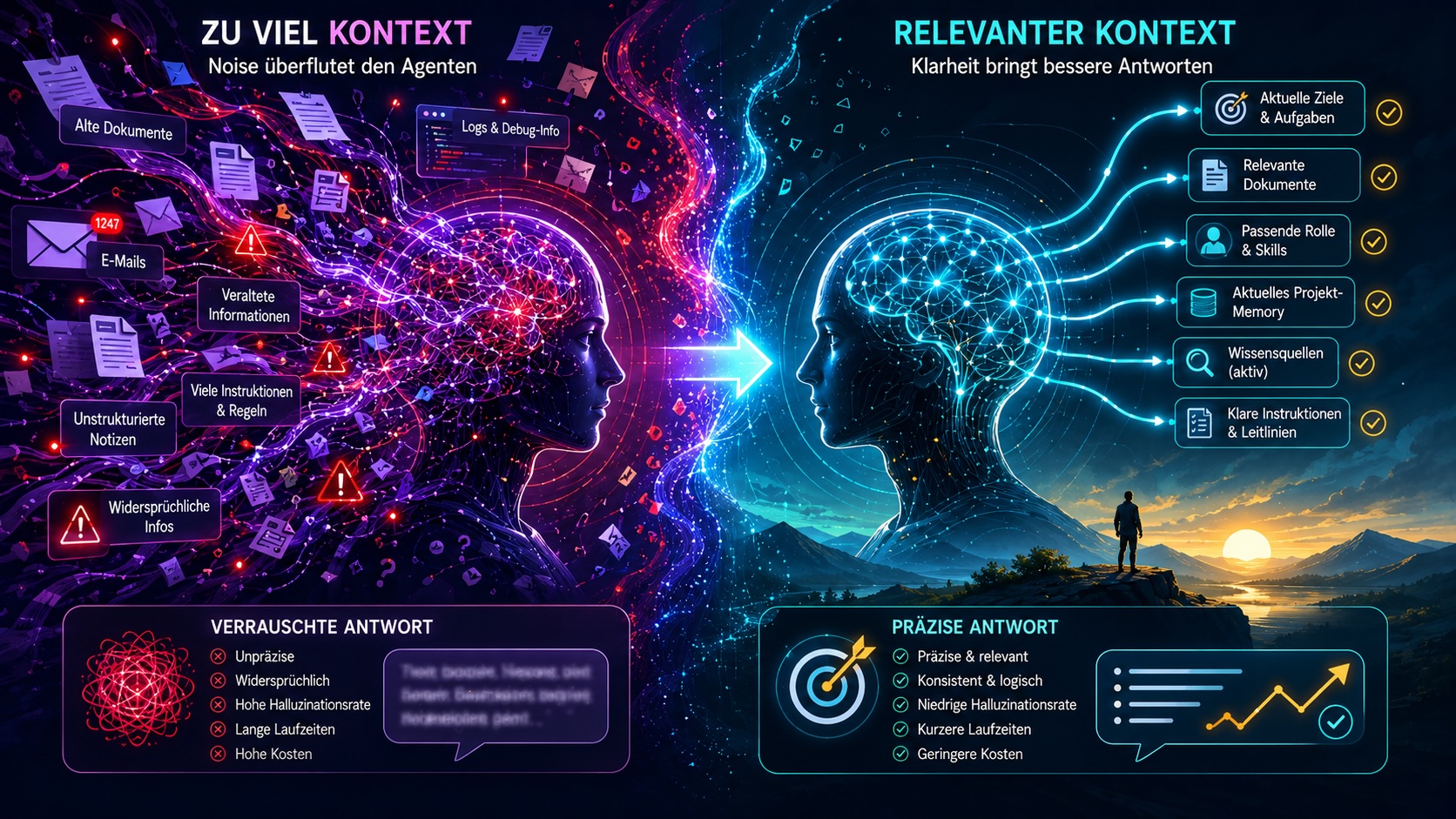
Große Kontextfenster reichen nicht. Mehr Kontext bedeutet nicht automatisch bessere Ergebnisse: Irrelevante Informationen konkurrieren um Aufmerksamkeit, verwässern Prioritäten und erhöhen die Halluzinationsrate. Der eigentliche Hebel liegt im Routing: Was ist relevant, wann, für wen, in welcher Tiefe?
Zu viel Kontext ist auch ein Problem.
Viele glauben: „Einfach alles in den Kontext werfen.“ Das Problem: irrelevante Informationen konkurrieren um Aufmerksamkeit. LLMs haben zwar große Kontextfenster, aber keine unbegrenzte Aufmerksamkeit.
Schlechtere Antworten
Relevante Signale gehen im Rauschen unter.
Verwässerte Prioritäten
Was wichtig ist, wird gleichgewichtet mit Beiwerk.
Höhere Halluzination
Mehr widersprüchliche Inputs erhöhen die Fehlerquote.
Höhere Kosten
Mehr Tokens, längere Laufzeiten, teurere Aufrufe.
Das eigentliche Problem ist nicht zu wenig Kontext, sondern zu viel irrelevanter Kontext.
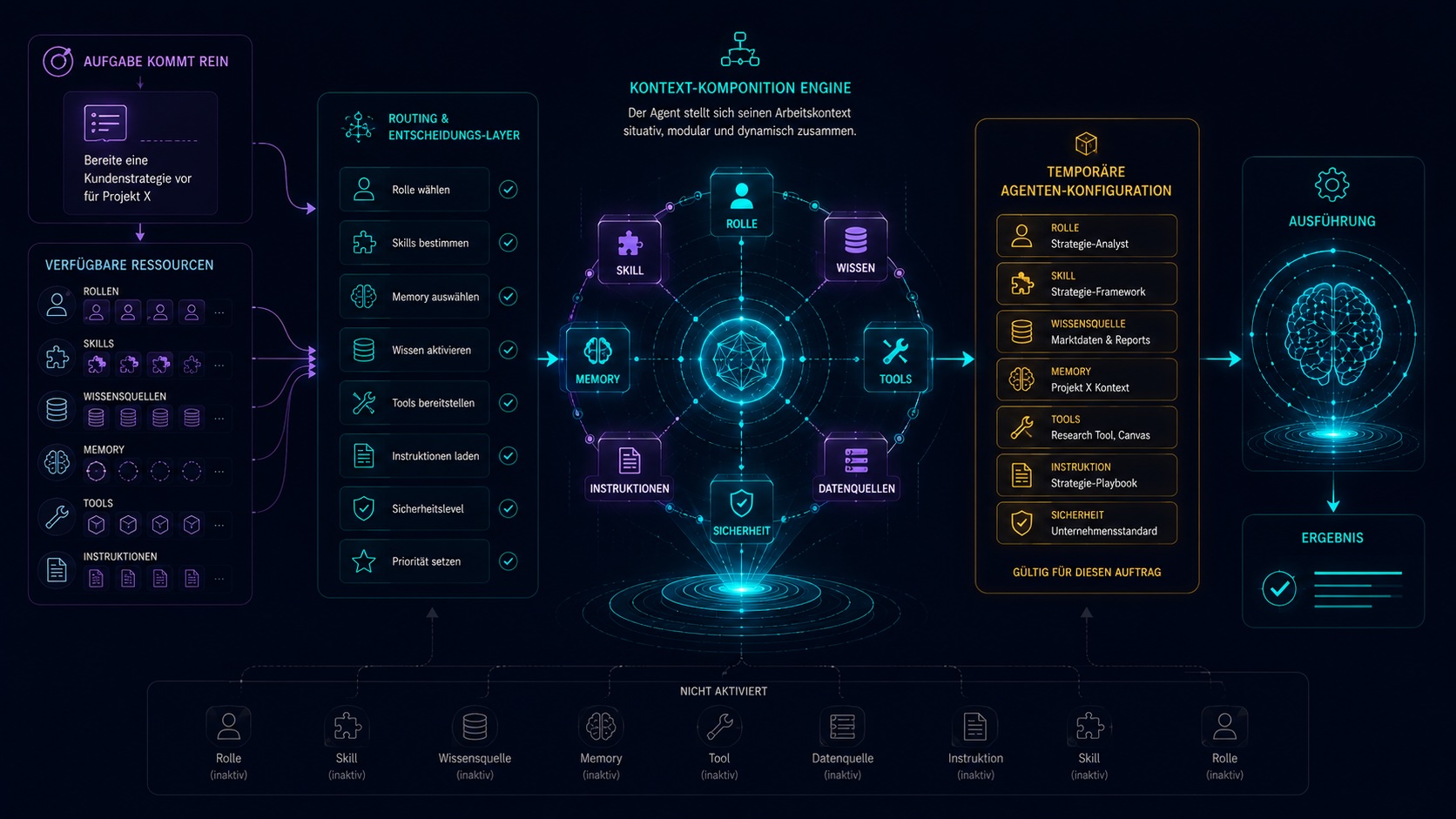
Der Agent baut sich seinen Kontext selbst zusammen.
Moderne Agenten sind nicht statisch konfiguriert. Wenn eine Aufgabe reinkommt, entscheidet ein Routing-Layer dynamisch, welche Rolle, Skills, Memory-Quellen, Tools und Instruktionen aktiviert werden. Der Agent kompiliert sich zur Laufzeit selbst.
- 01Statisch.
Ein großer Systemprompt, immer dieselben Tools, derselbe Kontext. Funktioniert für eine Aufgabe. Bricht bei der nächsten.
- 02Dynamisch komponiert.
Pro Aufgabe entscheidet das Routing über Rolle, Skills, Memory, Wissen, Tools. Der Agent passt sich der Situation an.
Ein moderner Agent kompiliert sich seinen Arbeitskontext zur Laufzeit selbst.
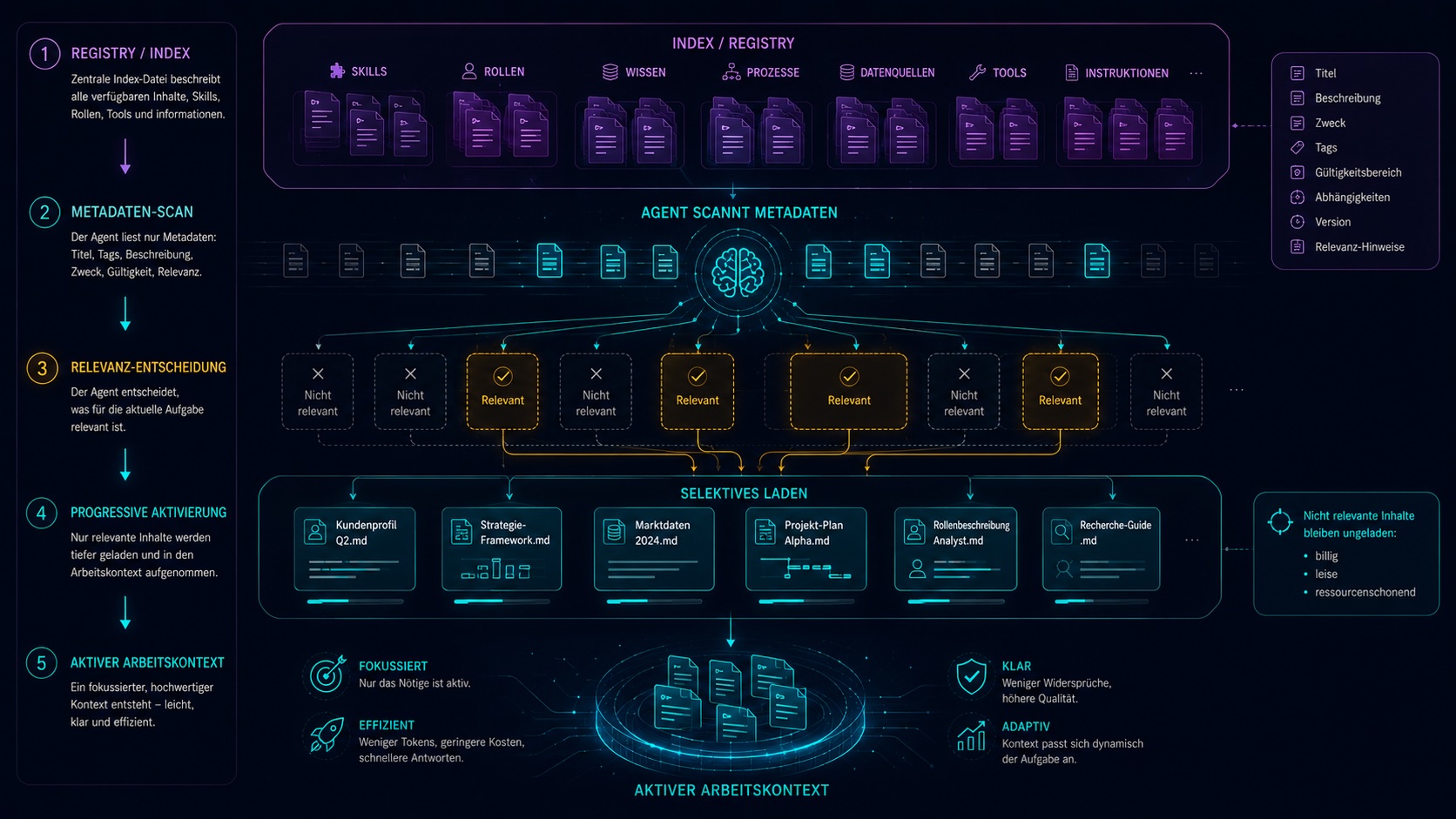
Index-Dateien & Capability Discovery.
Der Agent kann nicht alles vollständig laden. Er braucht Metaebenen zur Navigation. Eine zentrale Index-Datei beschreibt verfügbare Skills, Rollen, Wissensbereiche, Referenzen und Fähigkeiten. Jede Datei trägt YAML Frontmatter. Beschreibung, Zweck, Tags, Gültigkeitsbereich.
--- name: case-study-erstellen description: Aus Projektmaterial eine anonymisierte Case-Study-Skizze entwickeln. scope: project tags: [content, sales, beratung] inputs: [projektordner, freigaben] --- # Skill: Case Study erstellen ...
Der Agent liest zuerst nur Metadaten. Erst wenn etwas relevant aussieht, wird die volle Datei in den aktiven Kontext geladen. Progressive Aktivierung statt brutalem Vollload.
Gute Systeme laden selektiv. Nicht maximal.
Atomare Instruktionen statt Mega-Systemprompts.
Große Masterprompts erzeugen Konflikte, Unklarheit, Noise und schlechte Wartbarkeit. Besser: kleine, testbare, versionierbare und kombinierbare Instruktionen. Wie spezialisierte Module statt eines gigantischen Betriebshandbuchs.
- alles in einem Block
- schwer testbar
- versteckte Konflikte
- schlecht wartbar
- kaum versionierbar
- nicht teilbar
- klein und fokussiert
- einzeln testbar
- versionierbar
- kombinierbar
- klar abgegrenzt
- modular wartbar
Moderne Agentensysteme werden modular komponiert. Nicht zentral diktiert.
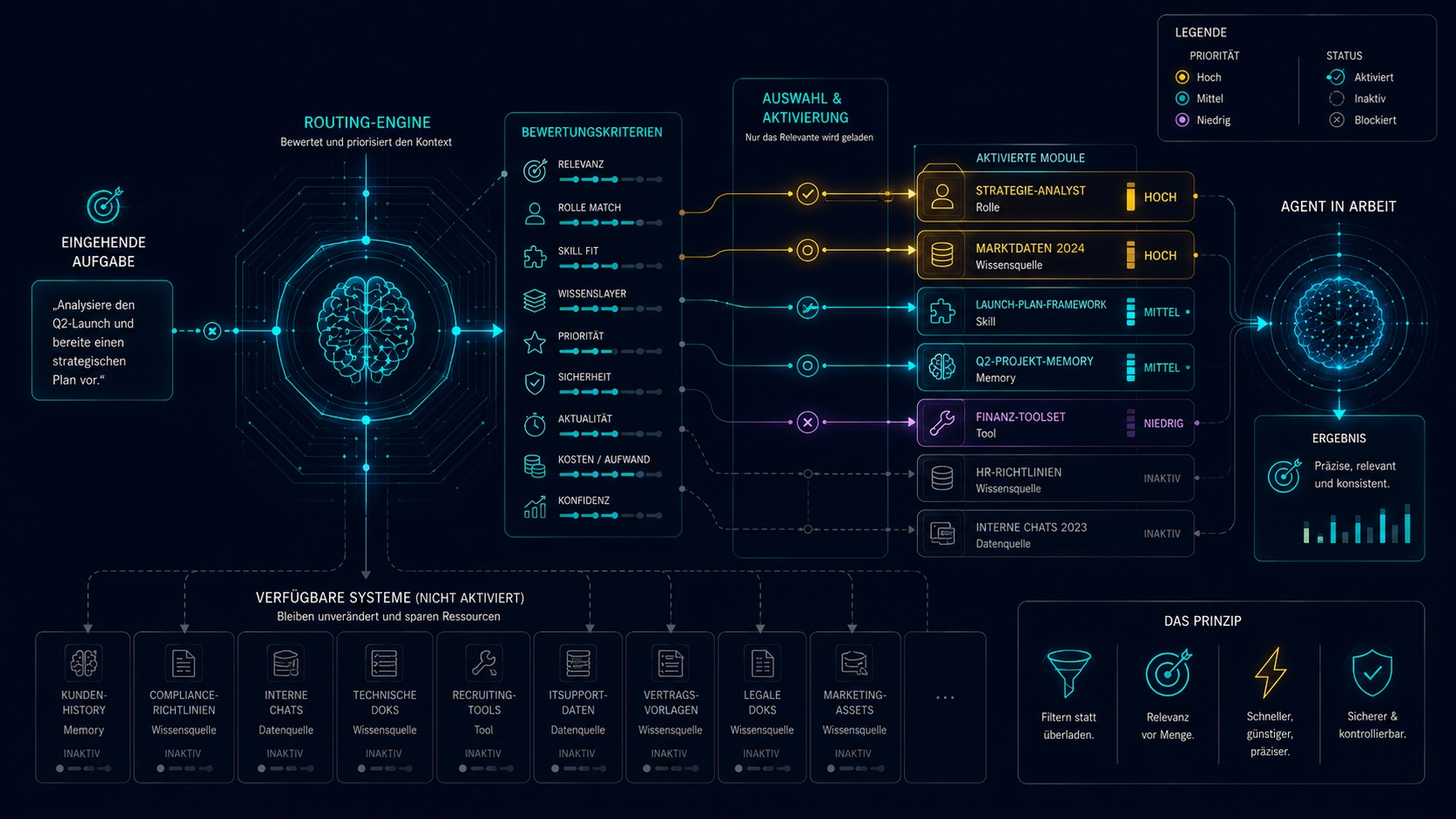
Routing wird wichtiger als Speicher.
Speicher wird billig. Aber relevante Aktivierung bleibt schwierig. Das Problem moderner KI-Systeme ist selten Wissensmangel, sondern schlechtes Routing. Die eigentliche Frage: Was ist relevant, wann, für wen, in welcher Tiefe, mit welchem Prioritätslevel?
- welche Module sind relevant?
- welches Wissen passt?
- welche Tools werden gebraucht?
- Zeitpunkt der Anfrage
- aktuelle Phase im Prozess
- Priorität der Aufgabe
- nur Metadaten
- Verdichtung
- volle Inhalte
- nichts
Intelligenz entsteht zunehmend durch Auswahl, Priorisierung, Orchestrierung.
Offene Probleme & ungelöste Fragen.
Dieses Feld ist noch extrem unreif. Aktuell baut fast jedes ernsthafte Agentensystem seine eigene Architektur. Wir befinden uns wahrscheinlich gerade in der Prä-Betriebssystem-Phase agentischer Systeme.
Relevanz messen
Wie quantifiziert man, was zur Aufgabe gehört?
Drift verhindern
Wie bleibt die Komposition über Zeit kohärent?
Wissen versionieren
Wie geht man mit konkurrierenden Versionen um?
Qualität bewerten
Welche Kompositionen funktionieren wirklich?
Tausende Skills orchestrieren
Wie skaliert Routing über große Skill-Bibliotheken?
Widerspruchsfreiheit
Wie verhindert man konfligierende Instruktionen pro Lauf?
Wir bauen gerade die ersten Betriebssysteme agentischer Systeme.
Vier Heuristiken für gute Orchestrierung.
Auch ohne fertigen Standard kann man heute brauchbare Architekturen bauen. Vier Regeln, die zwischen funktionierendem Routing und Kontextchaos entscheiden.
- 01Metadaten zuerst.
YAML Frontmatter pflegen. Der Agent entscheidet anhand der Beschreibung. Nicht durch Vollload.
- 02Atomar statt monolithisch.
Skills, Instruktionen, Memory in kleinen kombinierbaren Einheiten halten.
- 03Selektiv aktivieren.
Nur laden, was zur Aufgabe passt. Lieber leere Slots als Rauschen.
- 04Routing sichtbar machen.
Welche Komposition wurde gewählt? Audit Logs, damit Debugging und Verbesserung möglich bleiben.
Die Zukunft agentischer Systeme liegt nicht in immer größeren Kontextfenstern, sondern in intelligenter Kontext-Orchestrierung.
Der Agent der Zukunft ist kein statisches System. Sondern eine dynamische Komposition aus Rollen, Skills, Wissen, Memory, Tools und Instruktionen. Je nach Aufgabe.
Vier Bewegungen. Mehr braucht es nicht für gute Kontext-Orchestrierung.
- 01Indexieren
Metadaten, YAML Frontmatter, Capability Discovery.
- 02Atomisieren
Skills und Instruktionen klein und kombinierbar halten.
- 03Routen
Pro Aufgabe die passende Komposition zusammenstellen.
- 04Beobachten
Routing-Entscheidungen sichtbar machen, lernen, anpassen.
Das eigentliche Betriebssystem zukünftiger KI-Systeme ist Kontext.