Sprache als
Wahrscheinlichkeit.
Vom Wahrscheinlichkeitsmodell zum scheinbar intelligenten System.
Ein LLM ist kein Wissensspeicher, sondern ein Wahrscheinlichkeitsmodell für Sprache. Qualität entsteht durch Kontext, Beispiele und Struktur, nicht durch magische Prompts.
LLMs wirken intelligent. Sie sind es nicht. Zumindest nicht im menschlichen Sinn. Sie kennen keine Wahrheit, haben keine Absicht und keine Erinnerung. Sie berechnen Wahrscheinlichkeiten für das nächste Token. Wer das versteht, prompted besser, hinterfragt gezielter und nutzt die Stärken bewusster.
Was ist ein LLM überhaupt?
Ein Large Language Model ist ein statistisches Modell, das auf riesigen Textmengen trainiert wurde, um die wahrscheinlichste sinnvolle Fortsetzung eines Textes zu berechnen. Token für Token.
- 01Es denkt nicht.
Ein LLM versteht nicht, glaubt nicht und kennt keine Wahrheit. Es hat keine Absicht und keine Erinnerung über die aktuelle Eingabe hinaus.
- 02Es rechnet.
Es berechnet Wahrscheinlichkeiten für das nächste Token, wählt eines aus, hängt es an und rechnet weiter. Dieser Loop erzeugt scheinbar flüssige Sprache.
Das Modell erzeugt die wahrscheinlichste sinnvolle Fortsetzung. Nicht objektive Wahrheit.
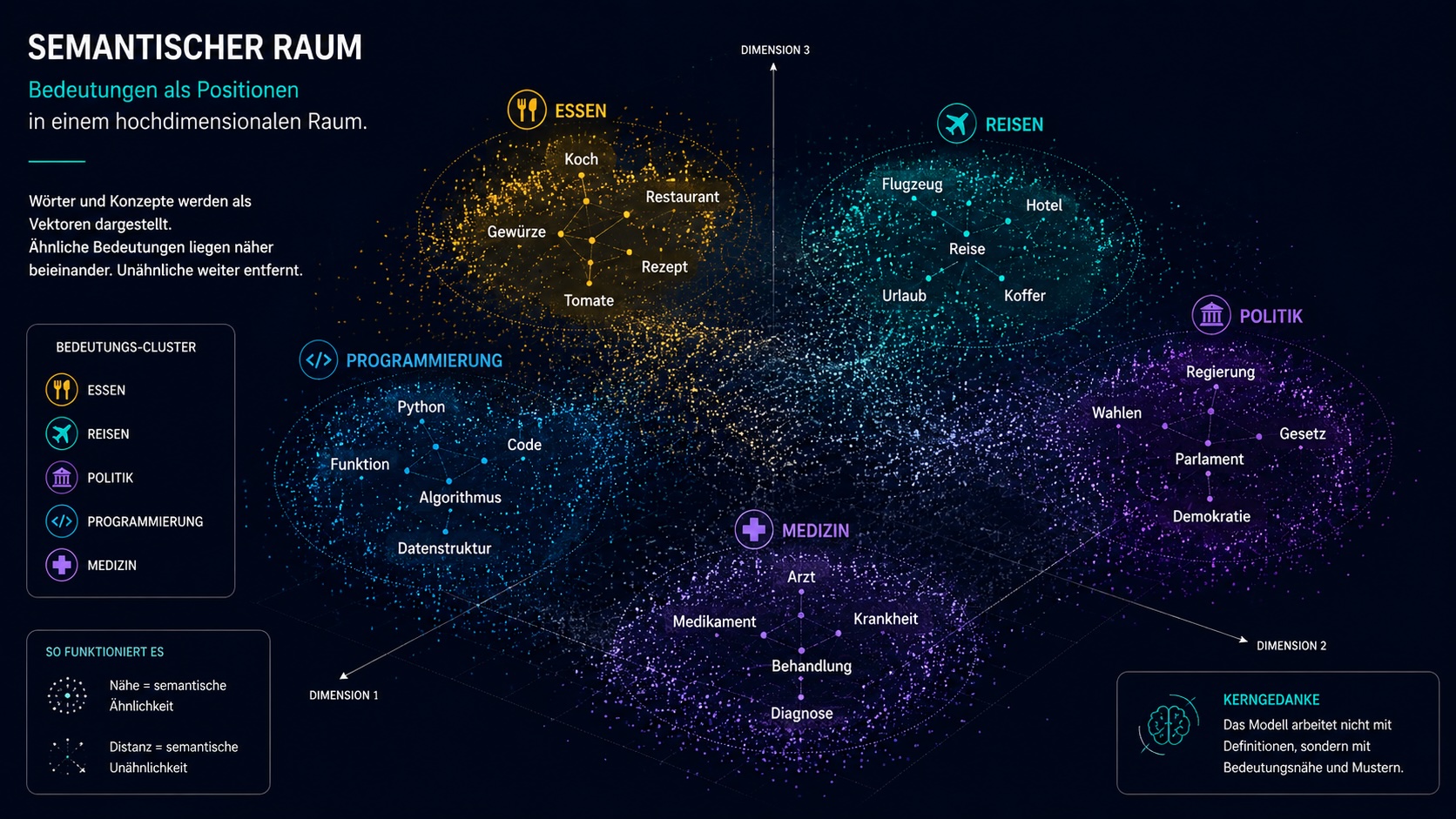
Tokens, Vektoren, semantische Räume.
Wörter und Konzepte werden mathematisch als Positionen in einem hochdimensionalen Raum dargestellt. Ähnliche Bedeutungen liegen nahe beieinander, unähnliche weit entfernt. Das ist keine Wörterbuchlogik, sondern eine Landschaft aus Bedeutungsbeziehungen.
- kleinste Texteinheit
- Wort, Wortteil oder Zeichen
- Basis aller Berechnungen
- „Restaurant“ ≈ 1 Token, „außergewöhnlich“ oft mehrere
- Position im Bedeutungsraum
- hunderte bis tausende Dimensionen
- kodiert Bedeutung und Kontext
- Grundlage für Ähnlichkeit
- Essen, Reisen, Politik
- Medizin, Programmieren
- themenähnliche Begriffe gruppieren sich
- Übergänge sind fließend
Das Modell arbeitet nicht mit Definitionen, sondern mit Bedeutungsnähe und Mustern.
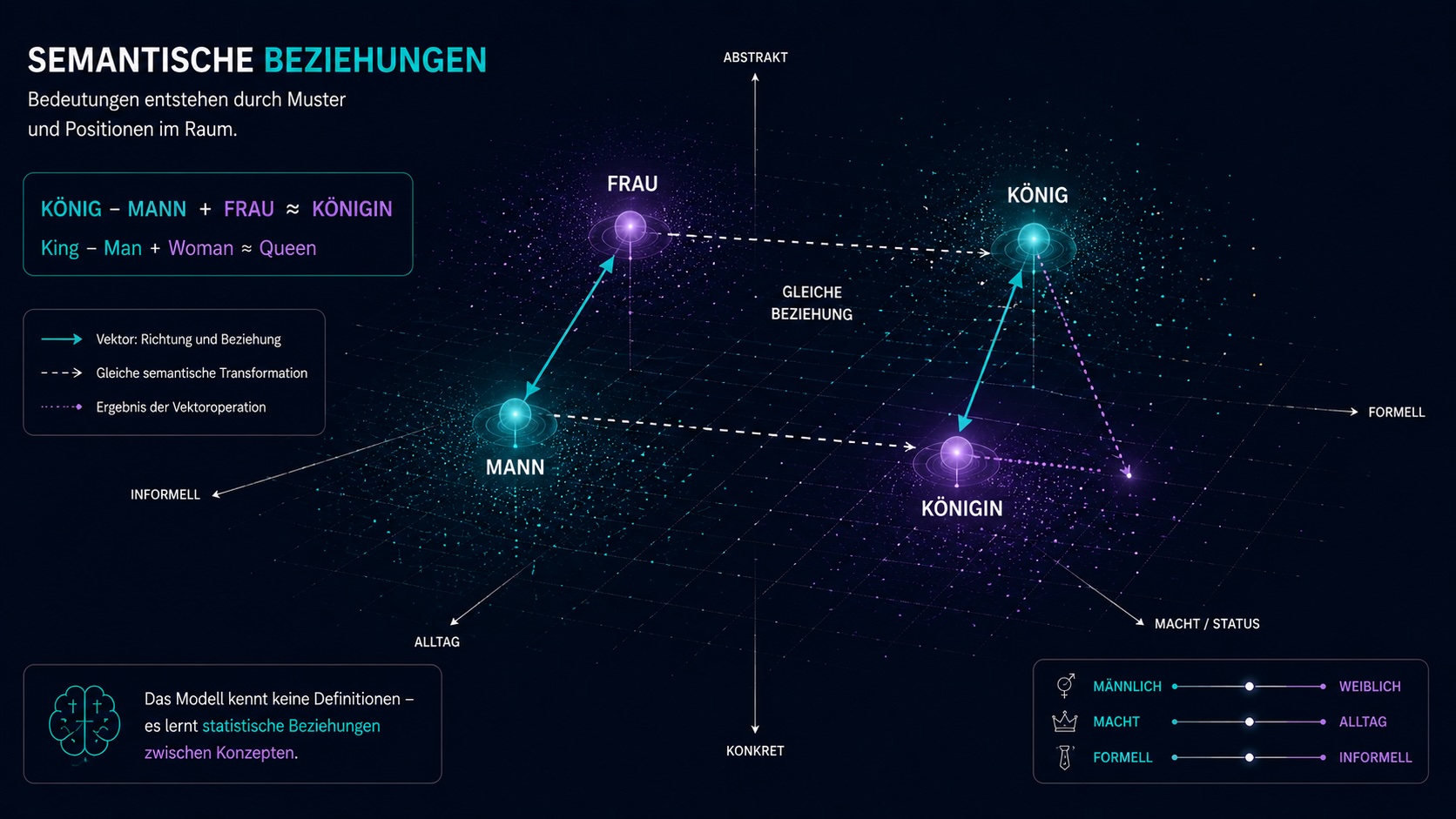
Das Königinnenbeispiel.
Wenn Bedeutung eine Position im Raum ist, dann sind Beziehungen Richtungen. Der Klassiker aus der Embedding-Forschung zeigt es am deutlichsten.
Königin
− Frau
+ Mann
─────────
≈ König- 01Muster statt Definition.
Das Modell weiß nicht, was eine Königin ist. Es kennt die Richtung „weiblicher Adel“ und kann sie auf andere Begriffe übertragen.
- 02Rollen, Analogien, Stil.
Dieselbe Logik trägt Übersetzungen, Stilwechsel, Tonalitäten und Rollenwechsel. Das Modell rechnet Bedeutungen, nicht Worte.
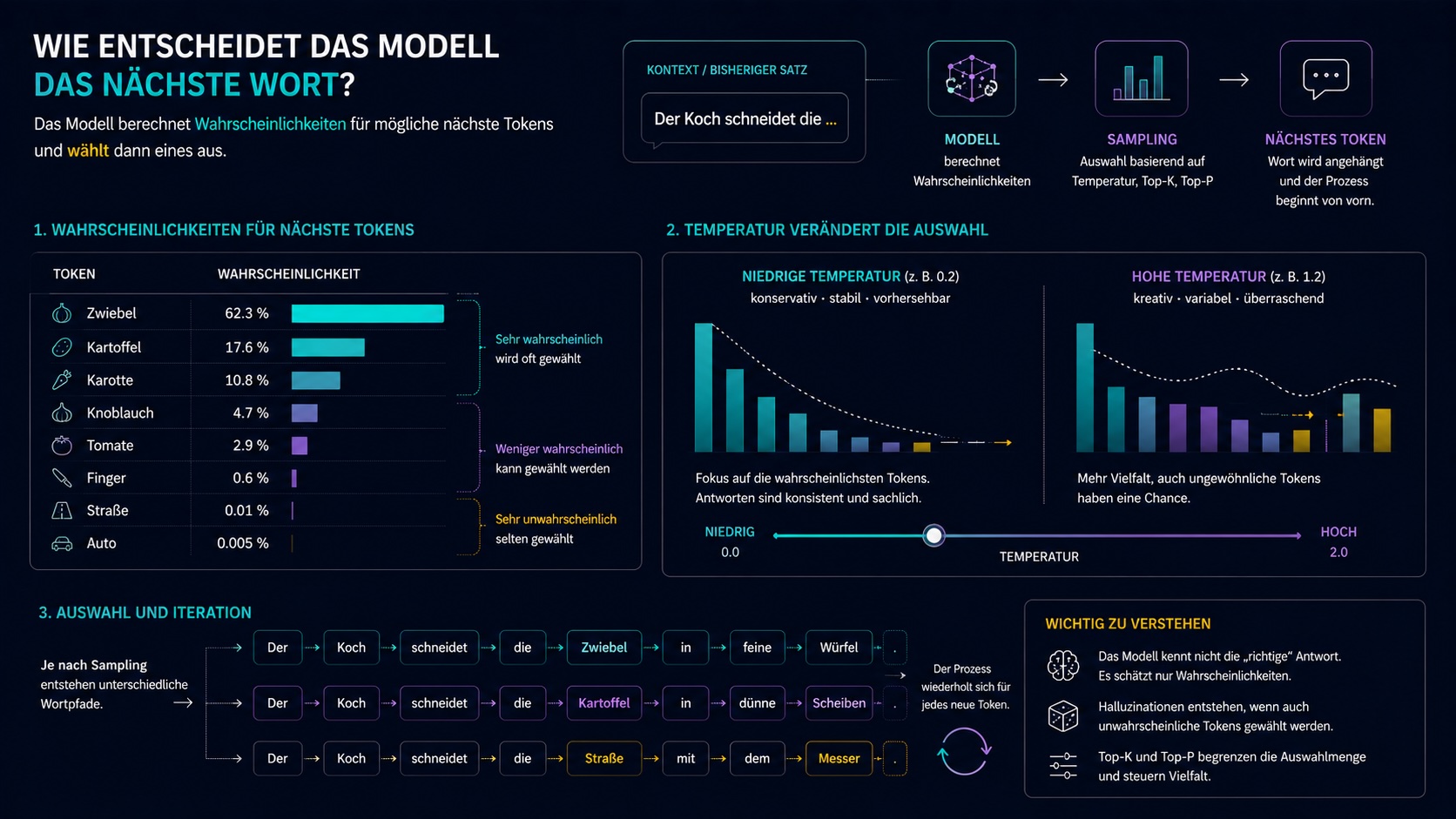
Wie entscheidet das Modell das nächste Wort?
Ein LLM ist wie ein Zug, der fährt und dabei immer wieder einen neuen Schienenabschnitt vor sich hinlegt. Token für Token. Jeder nächste Abschnitt hängt davon ab, welche Strecke bisher gefahren wurde.
Bei jedem Schritt berechnet das Modell eine Wahrscheinlichkeitsverteilung über alle möglichen nächsten Tokens. Drei Stellschrauben bestimmen, welches Token tatsächlich gewählt wird.
- niedrig: konservativ, stabil, vorhersehbar
- hoch: kreativ, chaotisch, überraschend
- verändert die Verteilung selbst
- steuert Stil und Risikofreude
- nur die K wahrscheinlichsten Tokens
- fester Schnitt
- schließt Ausreißer aus
- einfacher Filter
- dynamischer Wahrscheinlichkeitsbereich
- z. B. bis 90 % Gesamtmasse
- passt sich an die Verteilung an
- flexibler als Top-K
Dieselben Regler erklären Kreativität, Stil, Konsistenz und Halluzinationen.
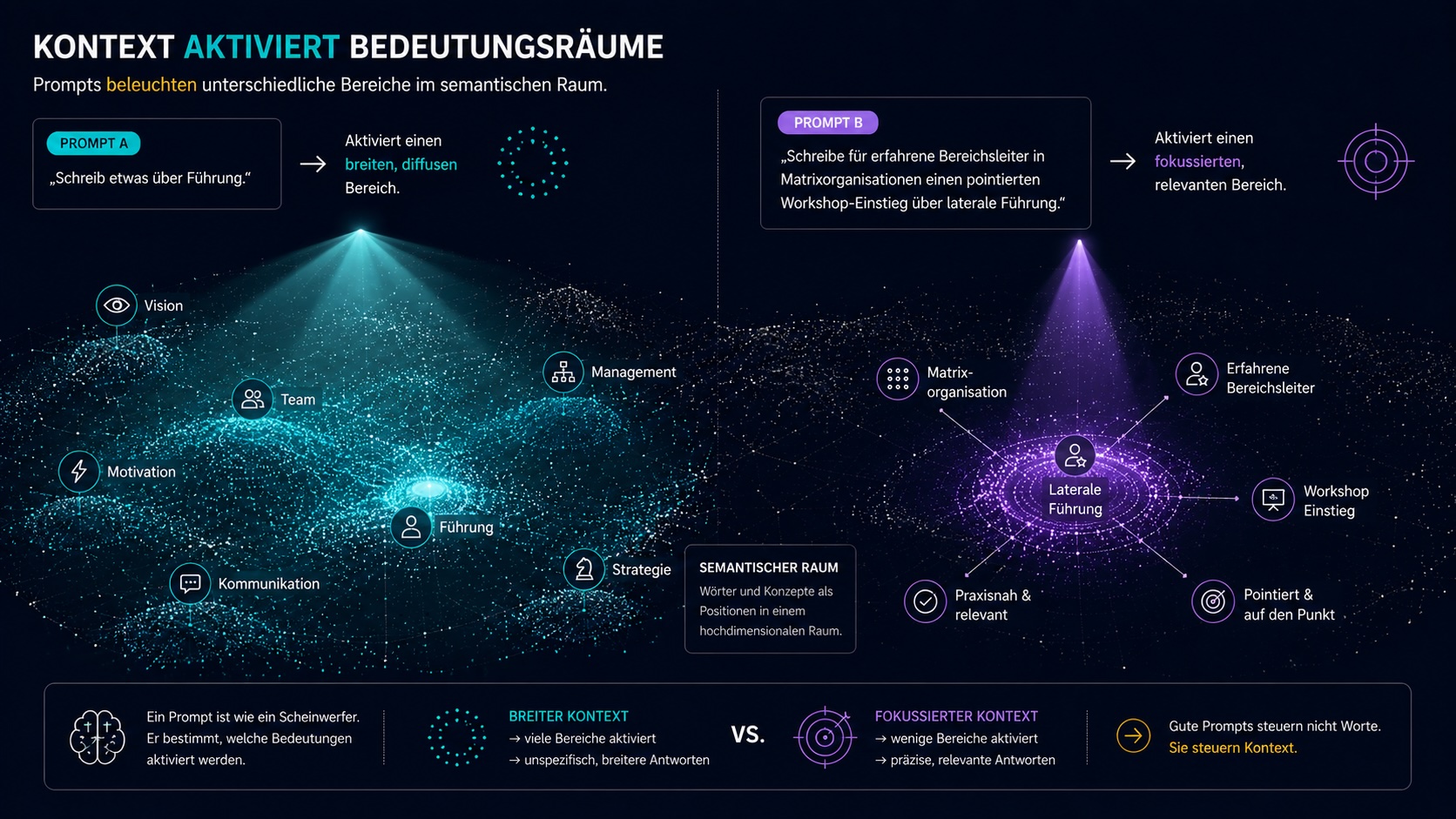
Warum Kontext so mächtig ist.
Ein Prompt aktiviert bestimmte Regionen im Bedeutungsraum. Je präziser der Prompt, desto fokussierter die aktivierten Cluster. Und desto relevanter die Fortsetzung.
„Schreib etwas über Führung.“
- aktiviert riesigen, unscharfen Bereich
- Ratgeber-Phrasen aus tausend Quellen
- keine Zielgruppe, kein Anlass
- generischer Output
„Schreibe für erfahrene Bereichsleiter in einer Matrixorganisation einen pointierten Einstieg in einen Workshop über laterale Führung.“
- spezifische Cluster
- relevantere Muster
- passendere Sprache
- klare Zielgruppenlogik
Prompting ist Kontextsteuerung. Keine magische Befehlsformulierung.
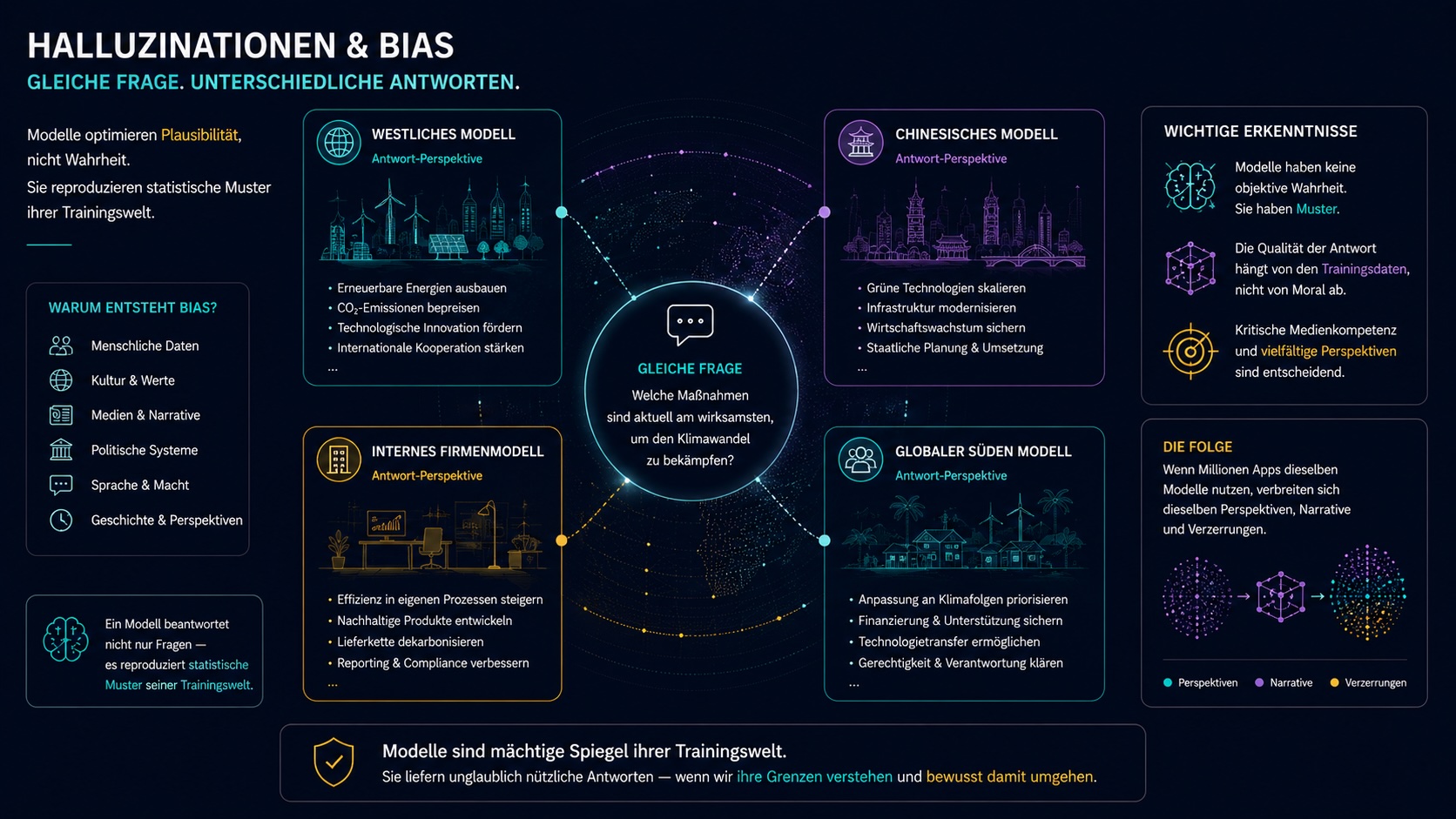
Halluzinationen und Bias.
Das Modell optimiert Plausibilität, nicht Wahrheit. Und es lernt aus menschlichen Daten: mit allen Mustern, Narrativen und Machtstrukturen, die darin stecken.
- plausibel klingender, erfundener Inhalt
- Quellen, Zahlen, Namen frei erfunden
- kein „weiß nicht“ eingebaut
- besonders riskant bei Faktenfragen
- Folge der Wahrscheinlichkeitslogik
- Trainingsdaten prägen Weltbilder
- Kultur, Sprache, Politik, Medien
- kein Bug, sondern Folge der Daten
- verschiedene Modelle, verschiedene Narrative
- Modelle reproduzieren Perspektiven
Ein Modell beantwortet nicht nur Fragen. Es reproduziert statistische Muster seiner Trainingswelt.
Wenn Millionen Apps dieselben Modelle nutzen, verbreiten sich auch dieselben Perspektiven. Kein Alarmismus. Eine Aufforderung zu kritischer Medienkompetenz.
Wo gute Modelle schlechte Ergebnisse liefern.
Menschen überschätzen das Modell und unterschätzen den Kontext. Sechs Muster, die fast jedes mittelmäßige KI-Ergebnis erklären.
Zu wenig Kontext
„Mach mal eine Präsentation.“ Ohne Zielgruppe, Anlass, Format und Inhalt bleibt nur Mittelmaß.
Keine Zieldefinition
„Schreib irgendwas dazu.“ Wenn niemand weiß, was gut wäre, kann das Modell es auch nicht treffen.
Kein Qualitätsmaßstab
Keine Zielgruppe, kein Stil, keine Kriterien. Das Modell rät, was „gut“ bedeutet.
Zu viele Aufgaben gleichzeitig
Analyse, Strategie, Text, Design und Research in einem Prompt. Alles wird flach.
KI wie Google behandeln
Ein Prompt, keine Iteration, keine Zusammenarbeit. Verschenkt die eigentliche Stärke.
KI blind vertrauen
Keine Verifikation, keine Gegenprüfung, keine Quellen. Plausibel heißt nicht richtig.
Ein LLM ist ein Wahrscheinlichkeitsmodell für Sprache. Kein Wissensspeicher.
Qualität entsteht durch Kontext, Beispiele, Struktur, Iteration, Planung und Daten. Nicht durch magische Prompts.
- 01Wahrscheinlichkeit statt Wahrheit
Das Modell wählt das nächste Token, nicht die richtige Antwort.
- 02Bedeutung als Raum
Wörter sind Positionen. Beziehungen sind Richtungen. Cluster sind Themen.
- 03Kontext aktiviert
Prompts beleuchten Regionen im Bedeutungsraum. Präziser Prompt, fokussierter Output.
- 04Plausibilität ≠ Wahrheit
Halluzinationen und Bias sind Folgen der Mechanik, keine Bugs.
Wer die Mechanik versteht, prompted gezielter und hinterfragt kritischer.